译介丨Mark Riedl:人工智能故事生成导论 (2021)
之前的几篇文章介绍了人工智能领域自动生成故事的一些方法,我在文章查阅文献时发现了Mark Riedl的这篇2021年的博客文章,感觉如获至宝。文章不仅对故事生成这个领域发展至今出现过的各种具有代表性的方法作了介绍,还穿插了大量作者自己的精彩洞见,在所有人都为chatGPT而兴奋到昏了头的今天,我认为特别有借鉴意义,因此做了翻译。
译者按
在我之前的两篇文章——2018年的人工智能与程序化叙事生成和2023年的大数据语言模型与程序化叙事生成中,我介绍了人工智能领域自动生成故事的一些方法,包括传统的基于图搜索、模拟和优化的方法,也包括近几年流行起来的基于机器学习特别是大语言模型(Large Language Models)的方法。
我在为这些文章查阅文献时发现了Mark Riedl的这篇2021年的博客文章(https://mark-riedl.medium.com/an-introduction-to-ai-story-generation-7f99a450f615),感觉如获至宝。文章不仅对故事生成这个领域发展至今出现过的各种具有代表性的方法作了介绍,还穿插了大量作者自己的精彩洞见,包括对故事本质的理解、对研究故事生成的意义的看法、传统方法和基于语言模型的方法各自的根本性问题——尤其是作者指出因为基于神经网络的方法目前阶段性的成功,就彻底否定传统的故事生成方法,无异于“把婴儿和洗澡水一起倒掉(throwing the baby out with the bath water)”——在所有人都为chatGPT而兴奋到昏了头的今天,我认为特别有借鉴意义。
翻译已获得作者授权。
厌氧菌
Mark Riedl

Mark Riedl是乔治亚理工大学交互计算学院的教授和机器学习中心的主任,主要研究以人为中心的人工智能(Human-centered artificial intelligence)——也就是能以更自然的方式理解人及与人交互的AI和机器学习技术。他在故事生成和理解(story understanding and generation)、计算创意学(computational creativity)、可解释AI(Explainable AI)等领域发表了大量的论文。
人工智能故事生成导论
自动化故事生成(Automated Story Generation)是我研究的众多课题之一。我已经有好几年没有教授我的人工智能讲故事的课程了。我编写了这篇入门读物,作为我认为我的学生需要知道的资源,以便开始自动故事生成的研究。任何对自动故事生成主题感兴趣的人都可能会从中得到有用的信息。由于我在近二十年来一直积极研究自动故事生成,这本入门书将在一定程度上偏向于我的研究小组和合作者的工作。
自动化故事生成是什么?
自动化故事生成是指使用智能系统,从一组最小的输入(minimal input)中产生一个虚构的故事。让我们把这个问题展开成不同部分来讨论。
- 叙事(Narrative):对一连串事件的叙述,这些事件有一个连续的主题并构成一个整体 (Prince, 1987).。一个事件描述了世界状态的某种变化。一个 "连续的主题 "意味着事件之间有某种关系——它是关于某件事情的,而不是一堆不相关事件的随机列表。究竟是什么”联系”起这些事件,还并不完全清楚,但我将在后面讨论这个问题。
- 故事(Story):人们会期待讲述故事的叙事要有某种特定属性。所有的故事都是叙事,但不是所有的叙事都是故事。不幸的是,我无法指出一套具体的标准,使人们将叙事视为故事。然而,一个强有力的可能的说法是,为了对观众产生特定的影响而采用的对事件的某种结构化处理。
- 情节(Plot):情节是叙事中主要事件的大纲。
我们可能要把自动故事生成(automated story generation)和自动情节生成(automated plot generation)区分开来。最近,有些人开始以这样的根据来区分故事生成与情节生成:系统的输出是否读起来像是一个主要事件的大纲,而不是用自然语言来描述故事中并非严格意义上的事件的要素,如描述、对话和其他阐述。区别似乎是:它读起来是像一个大概的事件大纲呢,还是像一个人可能在一本书中找到的东西。我不确定我会做出这样的区分,但我看到了这种区分对那些对表面形式而不是结构(两个同样重要和有效的观点)更感兴趣的人的吸引力。
“虚构”的标准将自动故事生成与其他讲故事的技术区分开来,如新闻写作,其中的事件是那些在现实世界中真实发生的。也就是说,新闻依靠现实世界作为 "生成器(generator)",然后创造出自然语言的文本叙述。新闻生成是一个重要的问题,但在我看来,这个问题应该从自动故事生成中分离出来。
“最小输入(minimal input)”是我为自动故事生成添加的一个标准,以区别于故事复述( story retelling)。故事复述是这样一个问题,其中大部分或全部的故事/情节都是给定的,自动化系统产生的输出是密切追踪输入的。例如,人们可能会给故事复述系统以某种简略或结构化的形式表述的事实记录,该系统可能会生成自然语言文本叙述,按顺序传达这些事实。在这种情况下,"故事 "是已经知道的,但讲述的表面形式是可变的。至于什么是 "最小"的输入集,是有争议的。它应该是故事开始的单一提示(prompt)吗?它应该是情节发展的起点和目标吗?它应该是需要被填入的少量情节点吗?给定的领域知识算是输入吗?对于机器学习系统,我们是否应该考虑将训练的语料库作为输入?这可能需要更多的工作,但我不愿意提供一个过于狭窄的定义。
为什么要研究自动故事生成?
我们可以从几个角度来看待这个问题。首先是应用的角度。除了人工智能系统能够写出人们愿意阅读的书这一宏大挑战之外,讲故事出现在社会的许多地方。
- 可解释的人工智能: 解释可以帮助人类理解人工智能系统的工作。对于连续的决策任务(sequential decision making tasks;例如机器人),这可能需要在解释中加入类似于故事的时序成分。
- 电脑游戏:许多电脑游戏都有故事或情节,这些故事或情节可以被生成或定制。超越了线性情节的交互式故事,是指用户在故事中扮演一个角色,并能够用他们的行动改变故事。为了能够对用户的新奇行动作出反应,需要有能力调整或重写情节。
- 训练和教育:基于探究的学习使学习者处于专家的角色,并且可以生成情景以满足教学需要(类似于上述互动故事)。
除了应用领域之外,故事的产生还触及了人工智能的一些基本研究问题。为了创造一个故事,就需要用语言进行规划。
为了讲好一个故事,一个智能系统必须拥有大量的知识,包括关于如何讲故事的知识和关于世界如何运作的知识。这些概念需要在智能系统的“心智”中存在某种基础,从而它能够讲述前后一致的故事。这种基础不一定是在视觉或物理操作方面;知识可以以共同的经验为基础。共同的经验与常识性推理(commonsense reasoning)有关,这是人工智能的一个研究领域,它被认为是许多实际应用的关键。
故事生成是了解一个智能系统是否真正理解了事物的一个很好的方法。要理解一个概念,必须能够将该概念付诸实践——讲述一个概念被正确使用的故事,正是这样做的一种方式。如果一个人工智能系统讲述一个关于去餐馆的故事——听起来很简单,但我们很快就会发现,当系统把基本的细节搞得一团糟时,它不理解的究竟是什么。
故事的生成需要一个智能系统拥有心智理论,一个关于听众的模型,以推理出什么需要说或什么可以不说,并仍然传达一个可理解的故事。
叙事学与叙事心理学
在深入研究技术之前,让我们看看我们可以从叙事学(Narratology)和叙事心理学(Narrative psychology)中学习的一些东西。叙事学是一个人文领域,关注叙事的研究。叙事心理学是心理学的一个分支,研究人类在阅读故事时头脑中发生了什么。
叙事学有很多的分支。作为一个技术人员,我发现结构叙事学 (Structural Narratology) 的价值最大,它为思考叙事的结构提供了框架。我发现他们的一些理论和框架是可操作的(这并不是说叙事学的其他分支没有用,只是我还不能直接将他们的贡献映射到系统工程中)。
结构叙事学在很大程度上借鉴了《叙事学:关于叙事的理论导论(Narratology: Introduction to the Theory of Narrative)(Bal(1998))》,从两个层面分析叙事。
- Fabula: “Fabula”是指对从故事开始到故事结束期间发生在故事世界中的所有事件的列举。在Fabula中,事件是按其发生的顺序排列的,但这并不一定与故事被讲述的顺序相同。最值得注意的是,故事中的事件不一定都存在于最后的叙事中;有些事件可能需要从实际讲述的内容中推断出来。比如说。“约翰离开了他的房子。三小时后,约翰到达白宫。约翰嘀咕着交通堵塞的问题”。这个故事显然包含了 “约翰离开家“和 “约翰到达白宫“以及 ”约翰喃喃自语“这些事件。我们可以推断出,约翰也开着车,并且被堵在了路上——这个事件没有被明确提及,而且会发生在 "出发 "和 "到达 "之间,而不是在第一条线索给出后。
- Sjuzhet: sjuzet是fabula中实际通过叙事呈现给观众的那些事件组成的子集。它并不要求按照时间顺序讲述,允许采用倒叙、闪回、省略号(时间上的空白)、交错、随机化(随机化)等非线性讲述方式。
(译注: Fabula和Sjuzhet这两个词实在找不到好的中文翻译,关于它们之间的区分更具体的请参看英文维基百科条目:Fabula and syuzhet)
有些人进一步区分了第三层,即文本或媒体,这是读者/观众直接接触的表面形式。文本/媒体是具体的文字或图像,从中可以推断出Fabula层面的叙事。
虽然在现实中,人类作家在上述所有三个层面上同时进行认知操作,但对故事生成系统的操作来说,fabula、sjuzhet和文本之间的区别是有用的。例如,一些系统使用了包含下述三个步骤的生成管线,其中(1)明确的fabula被生成为一个详尽的事件列表,(2)通过选择一个事件子集并可能重新排序来生成sjuzhet,以及(3)生成自然语言句子,以更丰富和更可读的细节描述sjuzhet中的每个事件。
叙事心理学的一个研究方向是读者在阅读故事时建立的心理模型。叙事理解的心理学研究指出当人类读者建立故事事件之间的关系时,因果关系的重要性(Trabasso 1982)。在叙事中,两个事件之间的因果关系指示,时间上的后一个事件部分是由时间上的前一个事件的存在促成的(叙事的因果关系与统计学或贝叶斯推理中的因果关系不同,在统计学中,随机变量之间的因果关系意味着一个随机变量的值会影响另一个随机变量的值的分布)。叙述性因果关系可以是由于直接原因——车轮从汽车上掉下来导致汽车坠毁——或通过使能(enablement)——如果不打开点火装置就不会坠毁。
Trabasso(1982)认为,人类对叙事的理解涉及对故事中事件之间因果关系的建模。当事件e1发生在事件e2之前,并且如果e1没有发生,e2不可能发生时,两个事件e1和e2之间就存在因果关系。虽然因果关系意味着e1导致e2,但更准确的说法是,因果关系的存在体现了使能(enablement)性:e1使得e2能够发生。Graesser等人(1991)假设,读者也对故事世界人物的目标层次进行建模,认识到故事中的人物与现实中的人相仿,有自己的目标,并采取行动来使目标和意图得以实现。有些事件是目标事件,有些事件是次级目标事件,是实现最终目标事件的必要步骤。例如,"约翰射杀弗雷德 "这一事件可能是一个目标事件,之前还有一些次级目标事件,如 "约翰买枪 "和 "约翰装枪"。这些子目标事件在目标事件之前,也作为层次结构的一部分与目标事件相关。有些事件还直接导致角色形成一种意图,这种意图在故事的后期表现为目标事件(或至少是实现目标事件的尝试)。例如,"弗雷德威胁要绑架约翰的孩子 "可能是一个导致约翰打算向弗雷德开枪的事件。这就抓住了两个事件之间的直接原因的概念,并以人物的心理状态为中介。
非机器学习的故事生成方法
让我们谈谈具体的技术。我们的讨论不可能是详尽无遗的,所以我试图建立一些笼统的类别,并给出每个类别的一些例子。这一部分考察那些并非基于机器学习的方法。非学习系统在自动故事生成的大部分历史中占主导地位。尽管对自然语言输出的强调减少了,但它们可以产生很好的情节。这些技术的关键性的本质特征——在大多数情况下——是对包含手工编码的知识结构的知识库的依赖。
故事语法
计算语法(Computational Grammar)是专门为用来决定一个输入序列是否会被机器接受而设计的。也可以反过来用来开发生成系统。最早的已知故事生成器(Grimes 1960)使用了一个手工设计的语法。其细节在很大程度上已被历史所遗忘。

1975年,David Rumelhart(1975)发表了一个表达故事理解的语法。此后,Thorndyke(1977)提出了一个故事语法。
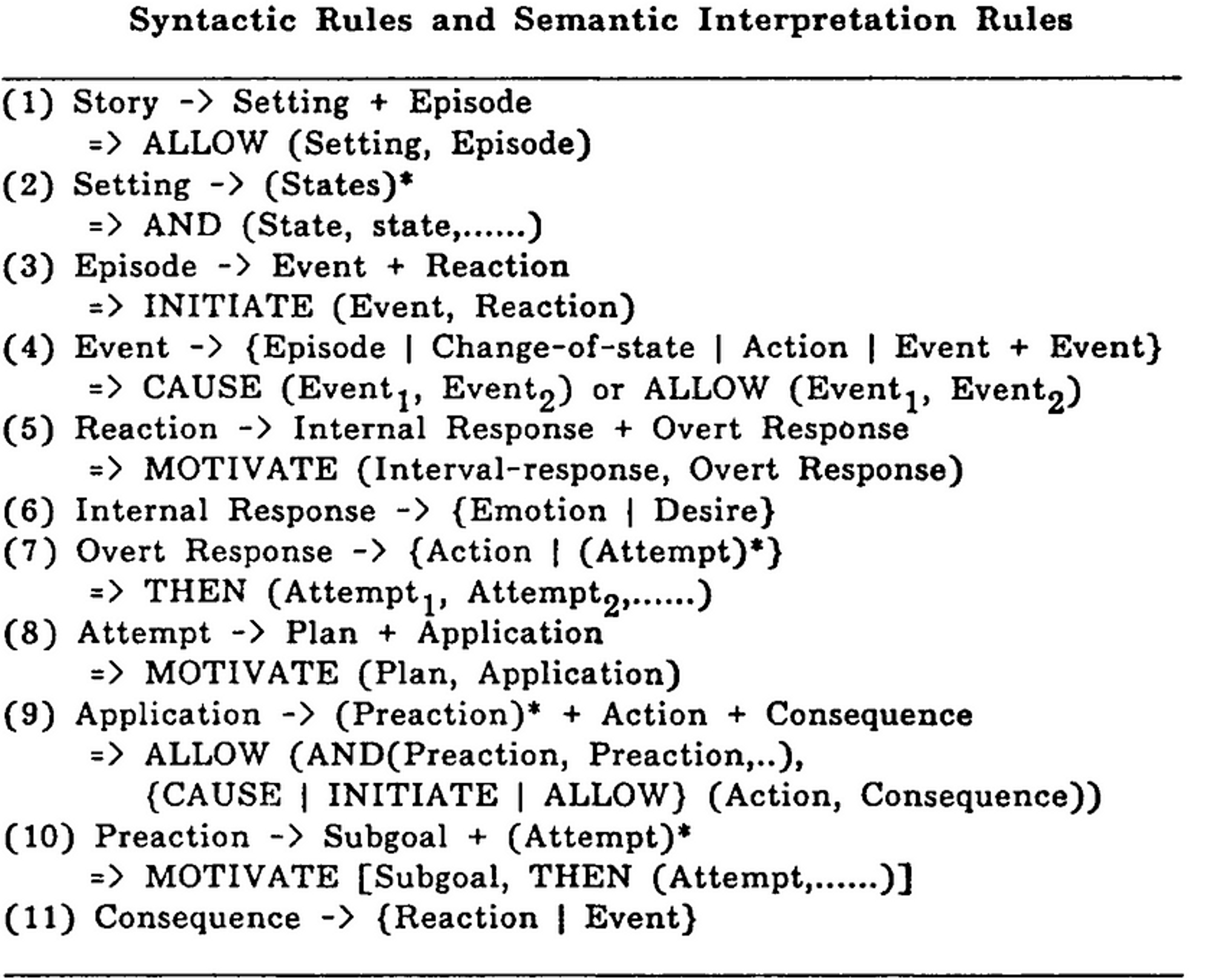
Black和Wilensky(1979)评估了Rumelhart和Thorndyke的语法,得出的结论是他们在故事的理解上并没有什么成果。Rumelhart(1980)回应说Black和Wilensky误解了。Mandler和Johnson(1980)认为Black和Wilensky是把婴儿和洗澡水一起扔掉了。Wilensky(1982)重新审视了故事语法,并对其进行了加倍的批评。Wilensky(1983)接着提出了一种语法的替代方案,叫做 "故事点(story points)",它类似于情节点的模式(见下一节),但不是生成的。Rumelhart继续研究神经网络,并发明了反向传播算法(back-propagation algorithm)。
故事规划器
故事规划器(Story Planner)的前提假定是:故事生成过程是一个目标驱动的过程。它将某种形式的符号规划器(Symbolic Planner)应用于生成故事的问题。规划器最后的输出是一个动作序列,这个动作序列就是故事。
被公认为第一个 “智能”故事生成器的系统是Tale Spin(Meehan 1977)。Tale Spin起源于故事理解(Story Understanding)领域的工作,将之逆转过来成为故事生成的方法。Tale Spin建立在两个核心思想之上。首先是概念依赖理论(Conceptual Dependency Theory),这是一种关于人类自然语言理解的理论,(为了简洁起见,)它将一切都归结为少量几个基本要素:ATRANS(转移抽象关系,如占有),PTRANS(转移物理位置),PROPEL(应用一种力量,如推),GRASP(抓住一个物体),MOVE(身体部位的移动)。其次是脚本(script),它是实现目标的程序性公式(由概念性的依赖关系组成)。给定一个角色的目标,Tale Spin会通过挑选脚本来生成一个故事。这可能导致主角或其他角色的进一步目标和进一步的脚本选择。

Tale Spin的一个更值得注意的贡献是 "误纺(mis-spun)的故事",它体现了脚本的知识工程和故事质量之间有紧密关系,就像那些以有趣的方式失败的例子所说明的那样。


(译注:是万有引力将亨利移动到了水里,因此万有引力一定与亨利在同一个地点,因此万有引力也在水里。而万有引力既不会游泳,又没有翅膀不会飞,也没有在附近的朋友来救它,所以不幸淹死了。)
随后的Universe系统对“规划(Planning)”的概念有了更现代的理解。我们现在将Universe称为贪婪的分层任务规划器(greedy hierarchical task planner)。Universe有一个角色生成器(Lebowitz 1984)和一个故事规划器(Lebowitz 1985)。Universe专注生成肥皂剧,它使用一个模版库,表明一个场景是如何进行的。该模版可以引用子模版。从一个高层次的场景目标(例如,"搅乱两个情人")开始,系统会选择一个描述如何使两个角色不开心的模版。该模版将包含一些子目标。系统将通过迭代分解子目标来构建故事。


在90年代中期,符号规划通过谓词逻辑(Predicate Logic)变得更加正规化。准确地说,规划器找到一个行动序列,将初始状态(以事实命题列表的形式给出)转变为目标状态成立的状态(以必须为真的命题列表的形式给出)。行动模式包括一个行动(action)、操作数(operands)、一个前提条件(precondition)和一个效果(effect)。前提条件是一组命题,必须为真才能执行一个动作。效果是对世界如何在命题变成真的和变成假的方面发生变化的描述。

自动规划有很多方法。部分顺序因果联系(Partial-Order Causal-Link, POCL)规划器通过寻求使目标条件成真的行动,然后寻求使这些行动的前提条件成真的行动,从目标向后反推到初始状态。这个过程一直持续到初始状态中列出的所有命题都能成立。有一种观点认为,最小承诺(Minimal commitement)计划类似于读者的心理模型,因为从某个行动的前提条件到另一个行动的结果的每一个链条都类似于“使能(enablement)”关系。
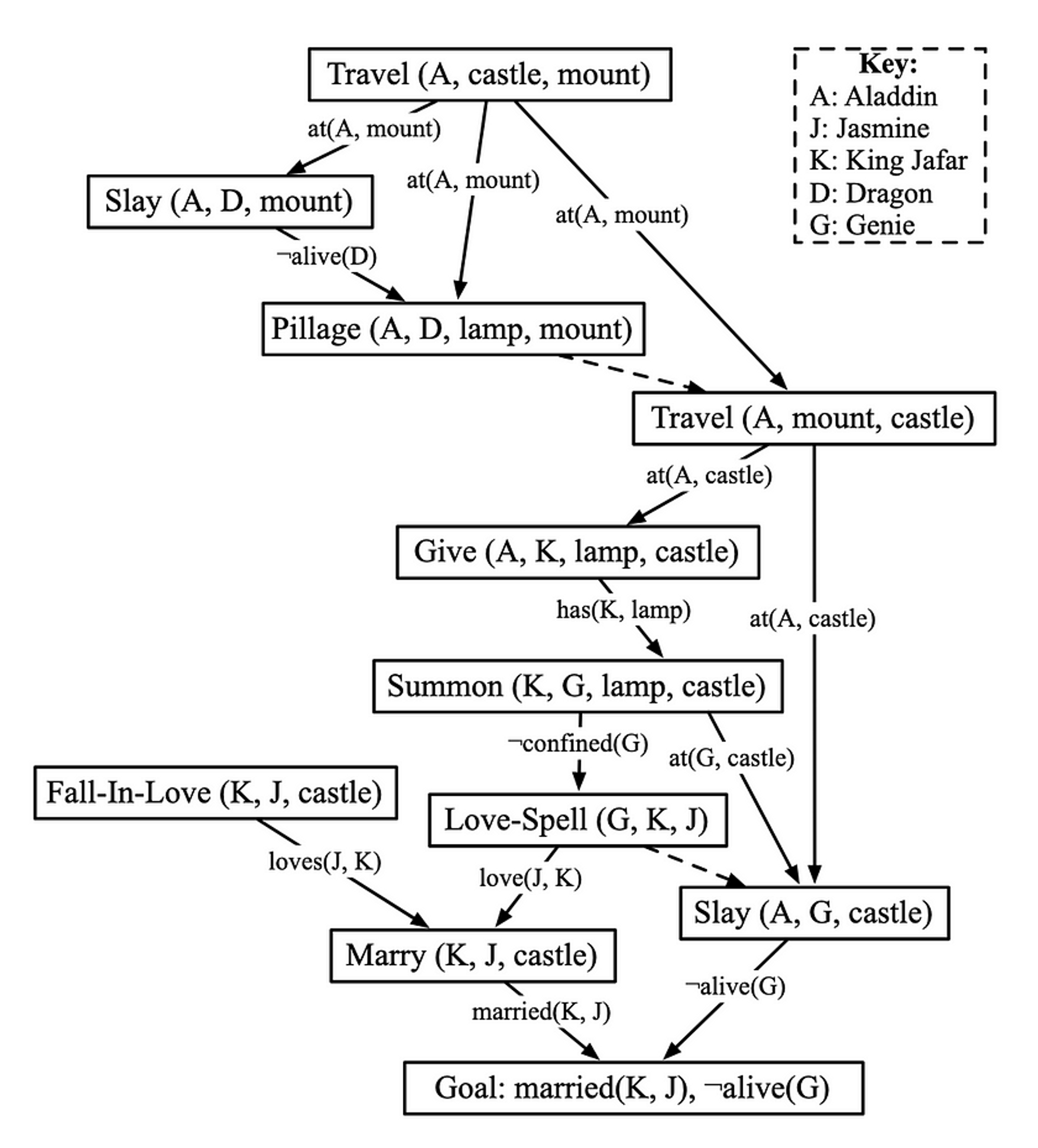
符号规划器的一个问题是,“使能”关系并不是故事的唯一考虑因素。如果一切都由先决条件的启用来驱动,那么最终看起来就像所有角色都在为一个共同的目标——给定的目标状态——而合作。我的Fabulist系统(Riedl 2010)使用了一种新发明的POCL计划器,它建立了一种计划结构,其中包含了人物目标层次和人物意图的表达。Fabulist使用三方框架:它首先生成一个作为fabula的计划数据结构,再选择行动作为sjuzhet的一部分,然后使用模板将行动渲染成自然语言。
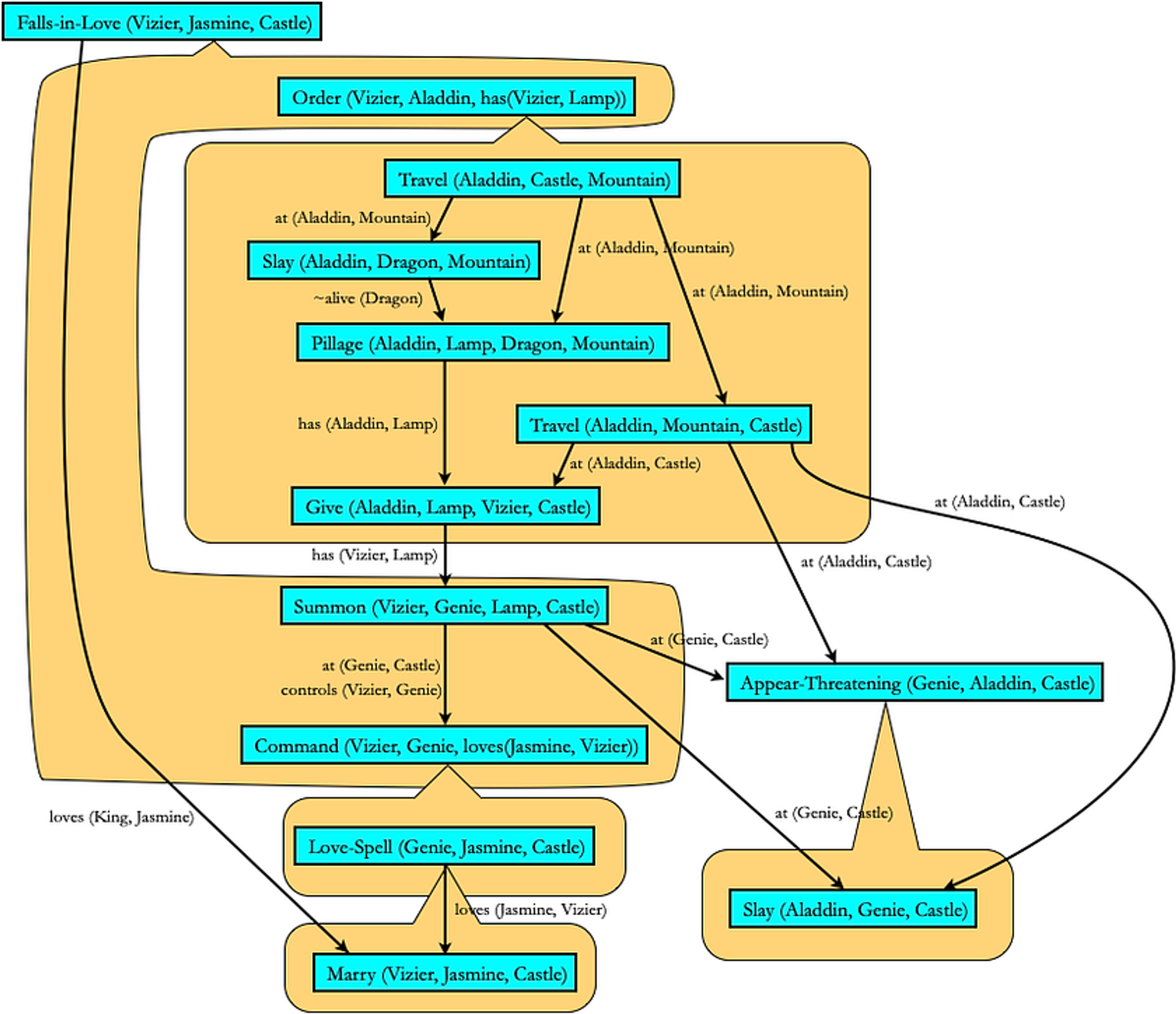
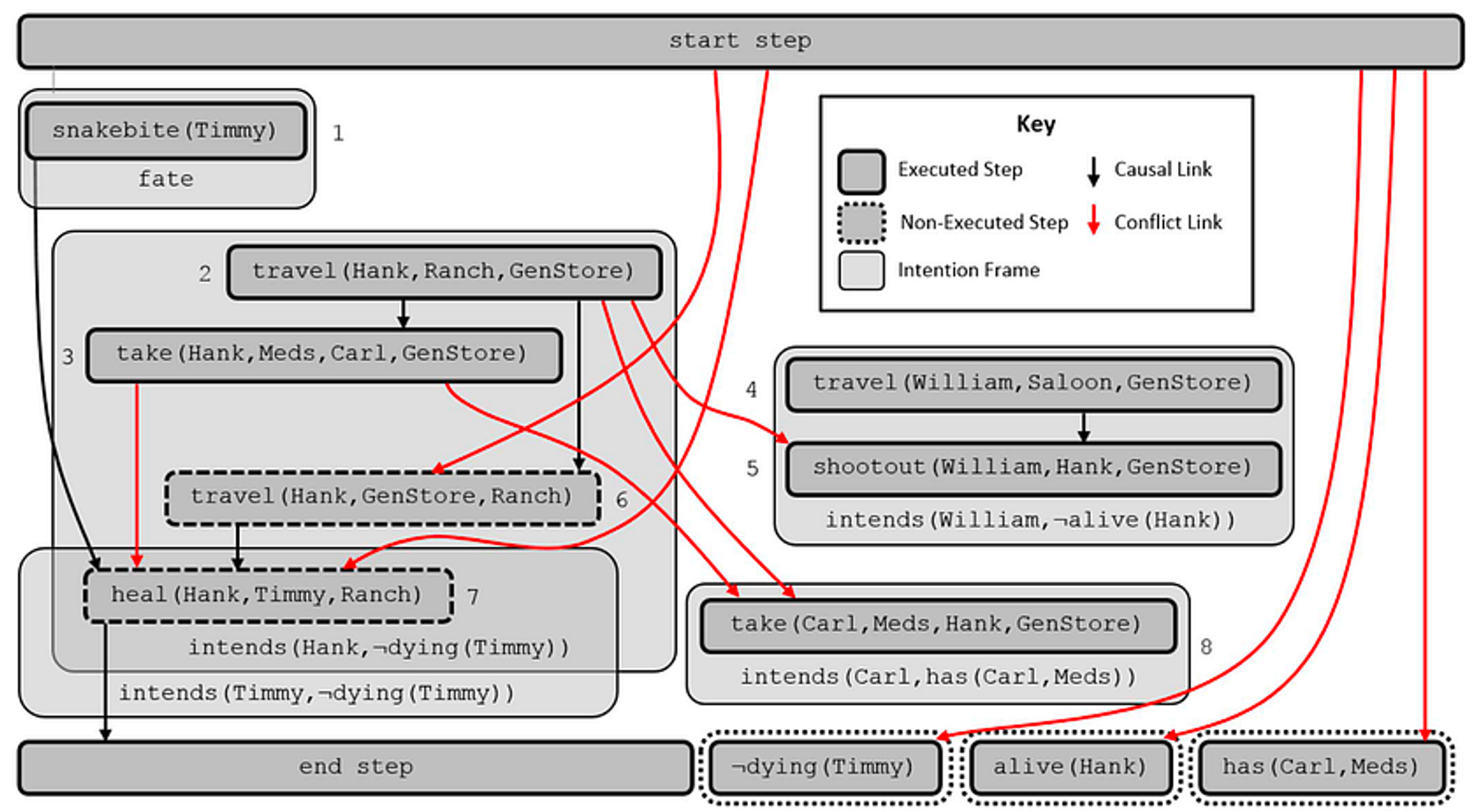
Stephen Ware(2014)进一步修改了POCL规划器,以确保人物冲突的出现(CPOCL)。规划器通常喜欢避免冲突,因为冲突打破了人物的一个或多个计划。
基于案例的推理
基于案例的推理(Case based Reasoning)是关于智能的一种理论,其基础是认为大多数推理不是从某个”第一原则(First Principle)”出发进行的,而是将对相关问题的解决方案的记忆调整适应到新的环境中来实现。当遇到一个问题时,个体会去检索一个较早的相关问题的解决方案,将旧的解决方案应用于新的问题,调整旧的解决方案以更好地适应当前问题的需要,然后储存新的解决方案。
我们有理由相信,人类讲故事是通过将已有的故事改编到新的上下文中。基于案例推理的故事生成方法通常假定个体可以访问现有的故事库,并使用上述的“检索-应用-改编-存储”的过程将一个旧的故事(或几个旧的故事)转化为一个新的故事。
Minstrel系统可以说是最著名的基于案例的故事生成系统。它使用了很多特殊的改编规则。
ProtoPropp系统(Gervas et al. 2005)后来使用了更具一般性的改编技术。ProtoPropp使用了Vladimir Propp对俄罗斯民间故事的分析来构建一个案例库。
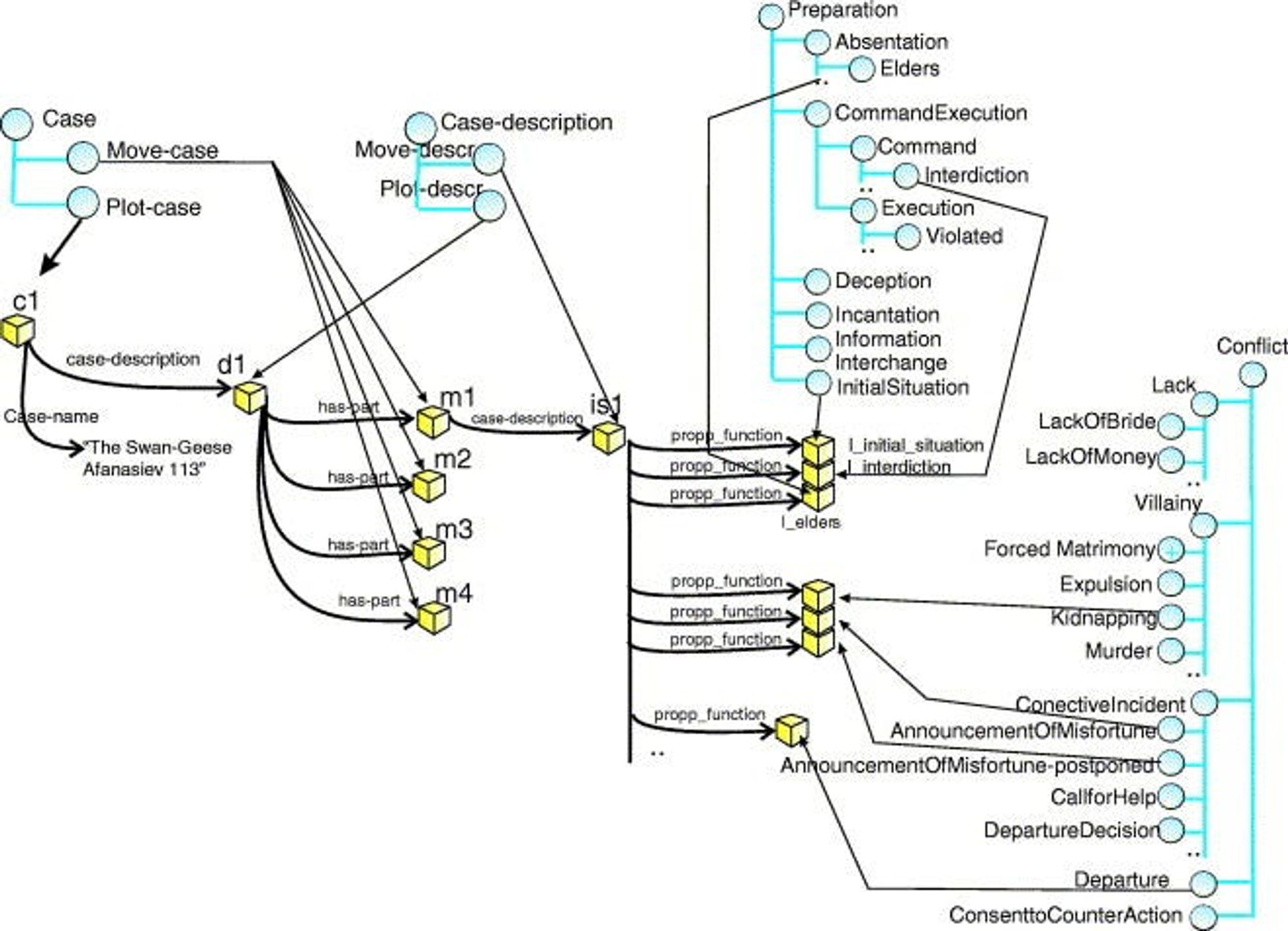
Mexica系统(Perez y Perez, Sharples 2001)编程实现了一种创造性写作的理论。它交替进行两个过程。第一个过程(参与, engagement)的操作有点像一个基于案例的推理器。它将迄今为止生成的故事与库中的现有故事进行比较,以产生一些有趣的延续。这些延续并不能保证与现有的故事元素连接起来,所以第二个过程(反思, reflection)使用了一个看起来很像倒推规划器的东西来修改新的片段,并添加新的动作来连接所有内容。
我的一些工作试图进一步调和基于案例的推理和POCL规划(Riedl 2008),并对基于案例的故事规划的适应阶段做了一些仔细的探索(Li and Riedl 2010)。与基于案例的推理相关的是,通过类比推理(analogical)的故事生成(Riedl and Leon 2009)。
SayAnything系统(Swanson和Gordon 2012)是基于文本的案例推理的一个例子。
基于文本的案例推理将大型文本语料库视为一种“非结构化的”案例库。大多数案例库都是结构化的,以便于检索和改编,因此对于非结构化的文本,检索和改编的难度要大得多。SayAnything系统从博客文章中挖掘故事,并从博客故事中检索片段以回应用户写的故事片段。该系统在人类和计算机之间轮流对故事进行补充。
基于人物角色的模拟
上述方法可以被认为是以作者为中心的(Riedl 2004)——故事生成者承担了一个单一的作者的职责,负责策划所有角色的所有行动和事件。
还有另一种生成故事的方法:对角色进行模拟。
在以角色为中心的模拟中,每个角色都是一个能够独立进行思考判断的个体。他们根据自己的信念、欲望和意图,对环境和其他角色做出反应。这方面的一个例子是Cavazza、Charles和Mead(2001)的系统,它使用了一个很现代的分层任务网络规划器(Hierarchical Task Network Planner)。每个个体都有一个目标并指定自己的计划。这些计划可能会发生冲突,需要另外一个思考主体来重新规划(在分层任务网络规划器中可以很快完成)。这个系统在技术上是一个交互式的叙事系统,因为用户可以向故事世界注入新的事实或信念,导致系统重新规划以作出回应。
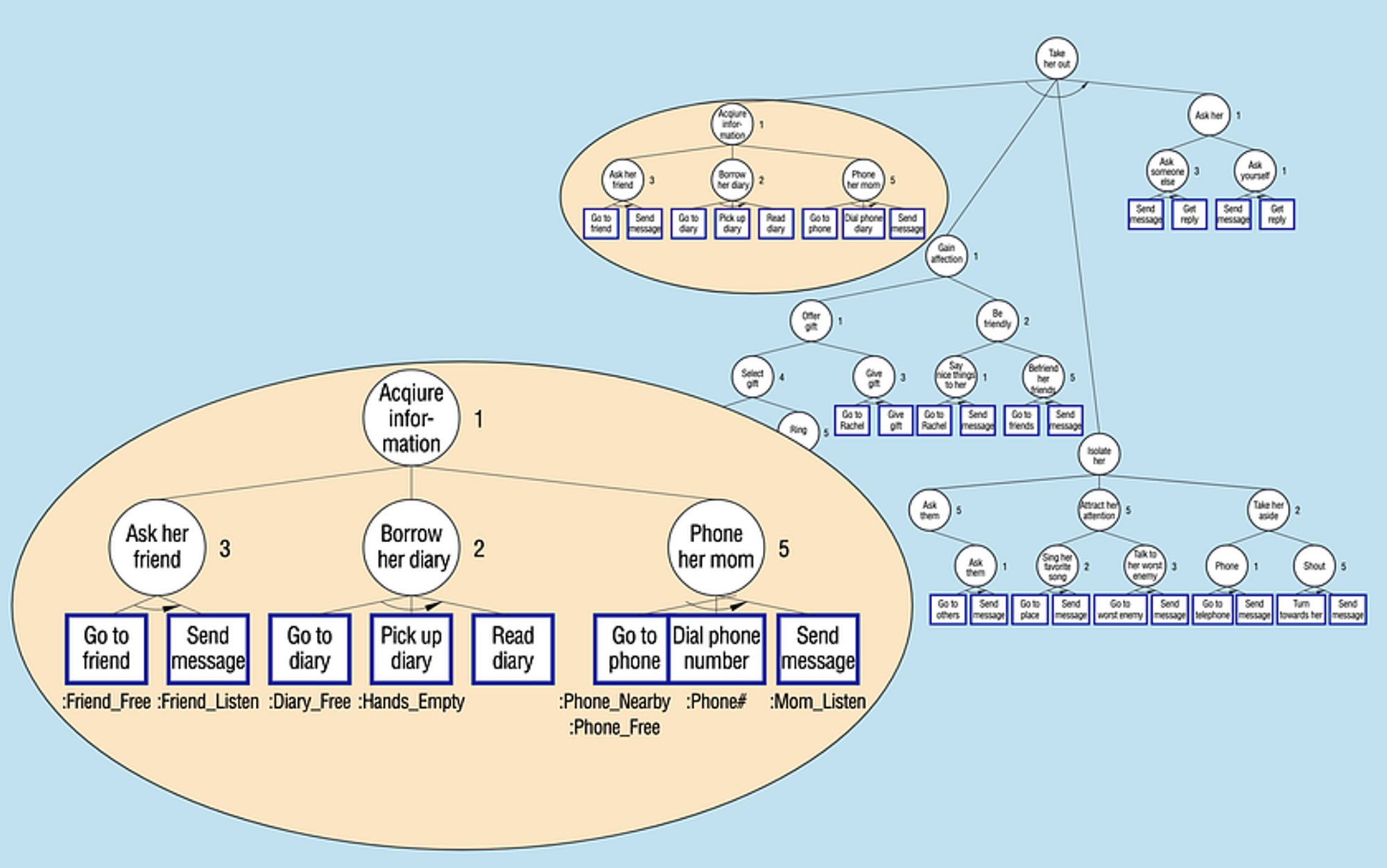
几乎所有能够对环境变化做出反应的智能体技术都可以应用于以角色为中心的模拟方法来生成故事。模拟方法的局限性之一是,对于角色开始执行时将发生什么,几乎没有保证。理论上,如果模拟是在对演员(actor)进行建模,而不是对角色(character)进行建模,那么他们将有一些能力根据讲故事的原则做出决定(Louchart和Aylett, 2007),而不是完全从角色的角度来操作(詹姆斯-邦德的模型与建立肖恩-康纳利的模型的区别)。在尝试对即兴戏剧演员进行建模方面也有一些工作(Riedl,2010;Magerko和O'Neill 2012)。
基于机器学习的故事生成方法
在本节中,我们将探讨不使用神经网络的机器学习方法。
非机器学习方法的挑战之一是,绝大多数的非机器学习系统要么需要编码成符号性故事模板(例如,分层级的情节模板、符号脚本、带有前提条件和效果的行动模板、以符号格式存储的案例等)。机器学习可用于获取构建这些模板所需的知识。Scheherazade系统(Li等人,2012年,2013年)维护了一个情节图的记忆,这些情节图是部分排序(partially ordered)的图,代表了某一主题的事件最可能的排序。例如,去餐馆的情节图可能有一些关键事件,如点菜、吃饭、付款、离开等等。图中的有向边代表时间顺序的约束,例如,付款发生在离开之前。这些图实质上类似于脚本,除了(a) 它们是部分有序的,而不是完全有序的;(b) 事件是任意的字符串。当Scheherazade被要求讲述一个关于某个主题的故事,但却没有相应的情节图时,它就会以群众外包(Crowdsourcing)的方式寻找故事的例子,然后学习一个情节图,从最常提到的事件中学习最可能的排序约束。该系统没有一个规定的字典来解释什么是 "事件"——一个事件是一组语义相关的字符串。一旦学会了情节图,生成过程涉及选择事件节点,以便不违反时间约束。由于事件是众包语料库中语义相关的句子集群,最终的故事可以通过选择节点的线性序列,然后从每个节点中选择一个句子来产生。

基于神经网络的故事生成方法
在过去的几年里,神经网络在文本方面的能力有了稳步提高。关于基于神经网络的故事生成技术的文献正在迅速增多,这就要求我在写作时只能关注一些我认为值得注意的系统和作品。
基于神经网络的语言模型
一个语言模型根据前文出现的符号序列的历史,学习接下来出现一个符号或者符号序列的概率。该模型是在一个特定的文本语料库中训练的。文本可以通过从语言模型中采样的方式生成。从一个给定的提示(prompt)开始,语言模型将提供一个或多个符号作为延续文本。提示加上得到的后续文本可以输入语言模型以获得再接下去的后续文本,以此类推。在故事的语料库上训练语言模型,意味着语言模型将试图模仿它从语料库中学到的东西。因此,从一个在故事语料库上训练的语言模型中采样,往往会产生看起来像故事的文本。
诸如LSTM和GRU的循环神经网络最初被探索用于文本生成(Roemelle和Gordon 2017,Khalifa等人 2017)。最初,如果故事训练语料库过于多样化,基于RNN的语言模型将很难产生不显得过于随机的序列。这是由于稀疏性(sparsity)——每个故事都很独特,故事中的任何句子或事件都可能是唯一的或几乎是唯一的。这使得在故事语料库上训练语言模型很困难。
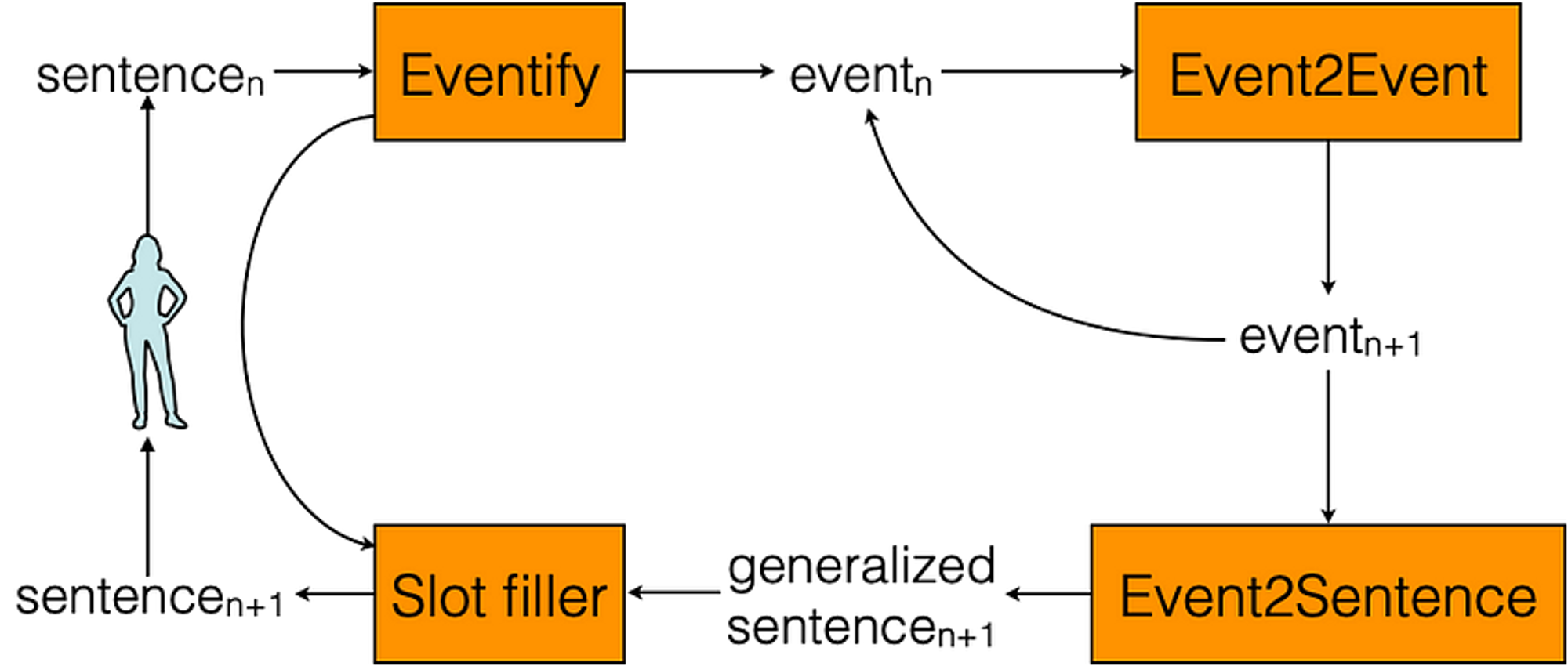
Martin等人(2018)通过将自然语言中的故事转换为事件五元组e=<s, v, o, p, m>的方式来解决这个问题,其中s是主语,v是动词,o是动词的直接宾语,还有,p是介词,m是伴随着介词的一个可选的附加名词。例如,"Sally多次在卧室里向她的出轨男友开枪 "将被表示为<Sally, 开枪, 男友, 位于, 卧室>。通过用WordNet的语义词类或VerbNet的语义动词框架类来替换五元组种的词,例如上述五元组可以变为<person-1, murder-42.1, male.2, in, area.5>,进一步抽象化了这些概念。理论上,这减少了稀疏性,而且事实表明,生成器可以学会产生比使用原始文本时更好的事件序列。 这种方法有一个问题是,人类很难读懂事件五元组,因此他们引入了第二个神经网络,将事件五元组转换为完整的句子。句子的 "事件化 "是一个有损失的过程,所以这个神经网络的任务是以增加上下文的方式恢复信息。这是一个具有挑战性的问题,相当于用自然语言重新讲述一个抽象的故事。人们发现,使用集群(ensemble)的效果最好(Ammanabrolu 2020)。
单一的语言模型并不能很好地区分人物角色,这些角色只是一些符号。Clark、Ji和Smith(2018)的工作是学习表示不同的实体,这样就可以产生关于不同角色的故事。
可控的基于神经网络的故事生成
神经语言模型的主要局限性之一是,它们是根据前文符号序列生成后续符号的。由于它们是回头看的(backward-looking),而不是向前看的(forward-looking),所以不能保证神经网络会产生一个含义连贯(coherent)的文本,或驱动到一个特定的叙事点或目标。此外,故事越长,早期的上下文被遗忘的就越多(要么是因为它不在可允许的上下文窗口内,要么是因为神经注意机制更偏重更近的历史)。这使得基于神经语言模型的故事生成系统成为 "花哨的胡言乱语者(fancy babblers)"——这些故事往往有一种意识流的感觉。大规模的预训练Transformer模型,如GPT-2、GPT-3、BART等,通过允许更大的上下文窗口,帮助解决了一些 "花哨的胡言乱语 "的问题,但这个问题并没有完全解决。作为语言模型本身,它们无法解决前瞻性的问题,以确保它们是朝着未来的东西建立的,除非是碰巧。
Tambwekar等人(2019年)使用强化学习(Reinforcement Learning)来微调一个序列到序列(sequence-to-sequence)的语言模型,以生成朝向特定叙事目标发展的故事后续。强化学习,一般来说,是一种可以用来解决序列行决策问题(sequential decision-making)的技术。然而语言模型的潜在空间对于真正的试错型(trial-and-error)学习来说太大。强化学习器是作为一个不可求导(non-differentiable)的损失函数(loss function)来使用的。但是,强化学习器如何知道故事后续是否正在接近一个特定的目标?该系统从故事语料库中提取动词的模式,根据每个动词离目标的远近对它们进行聚类(clustering),然后当语言模型产生的后续中有一个动词在下一个聚类中更接近目标时,就对它进行奖励。

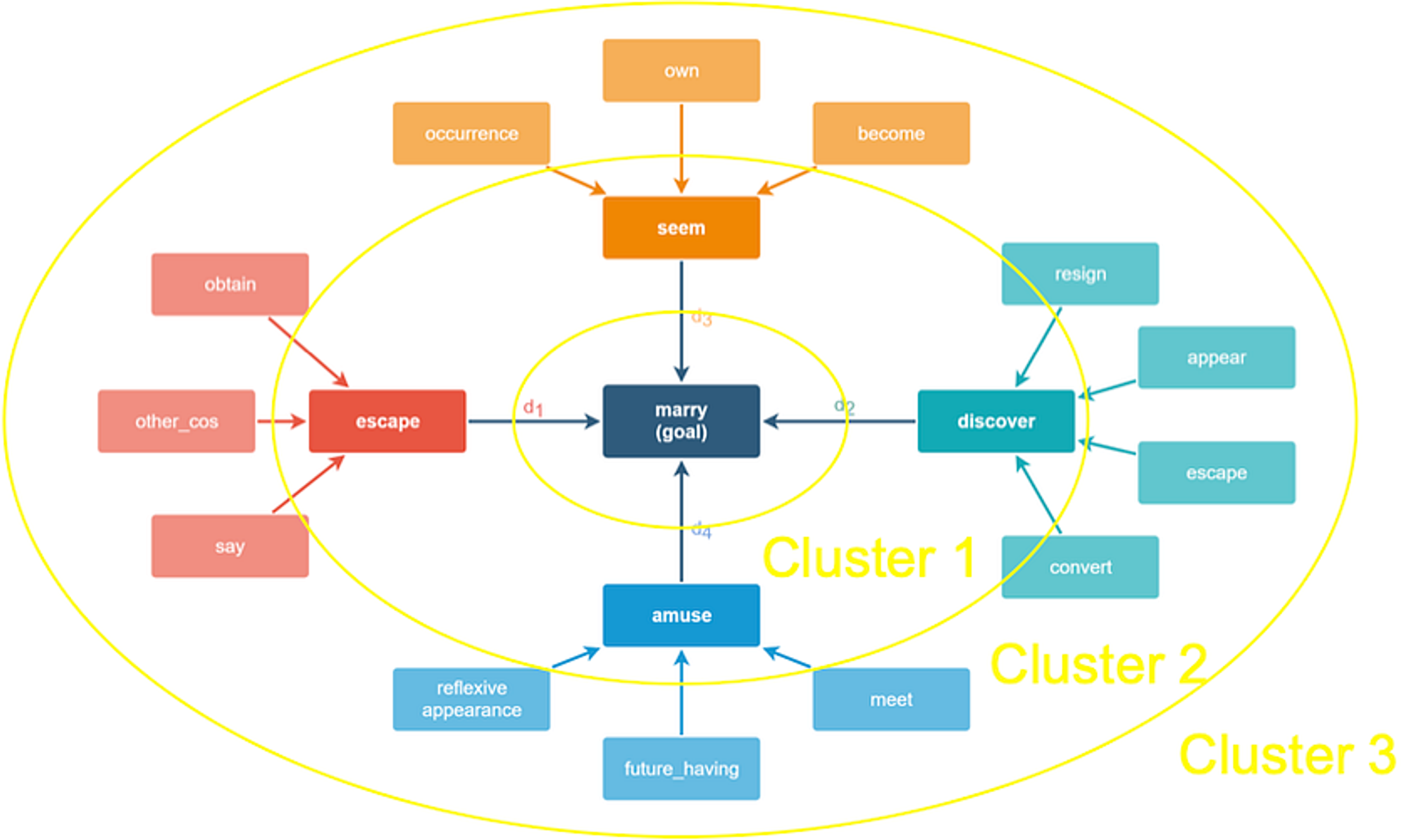
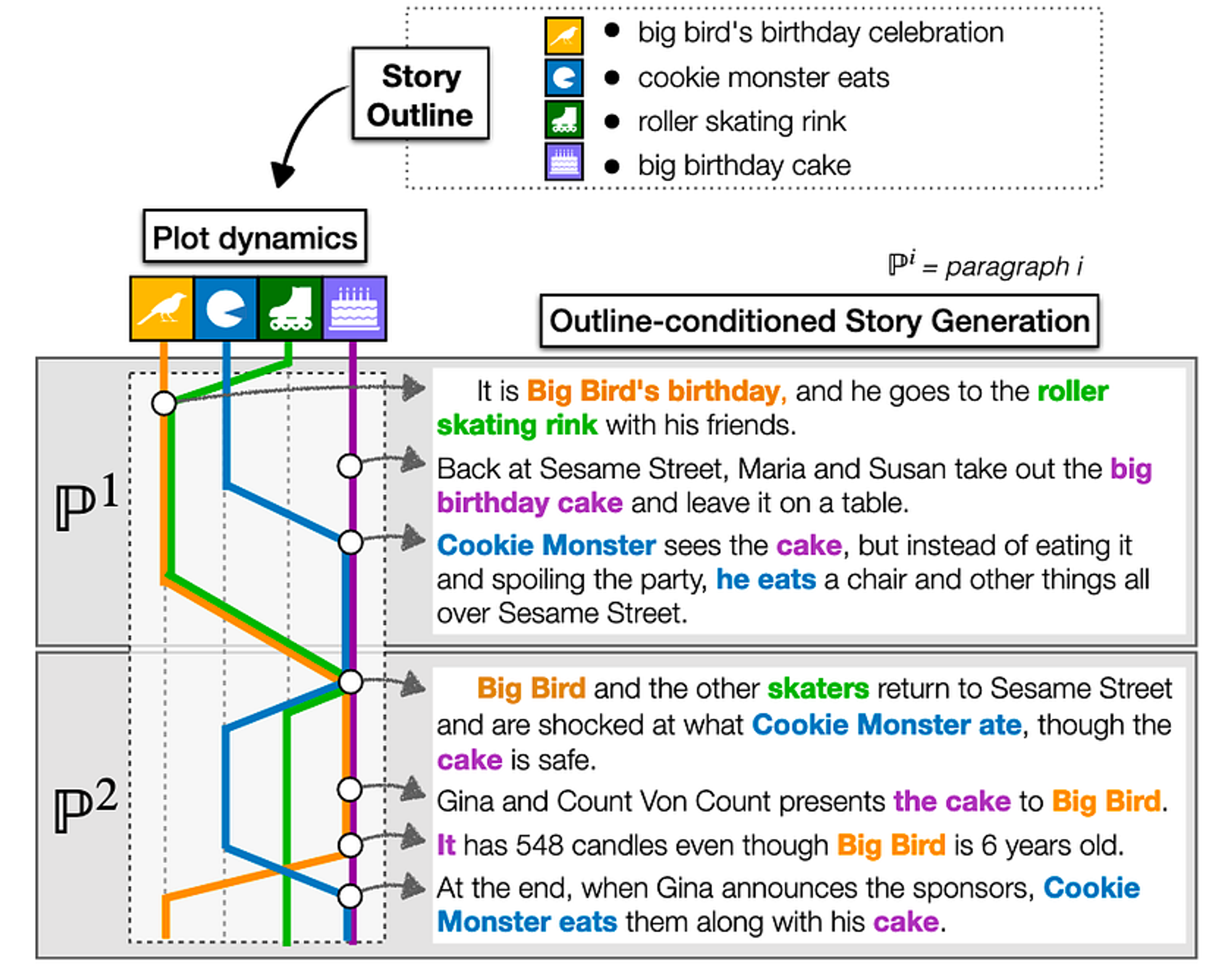
虽然通常语言模型得到的提示(prompt)输入是故事的第一行,但神经语言模型也可以以故事中需要出现的情节点为条件进行生成。这增加了某些事件在故事生成过程中发生的概率。分层融合模型(Hierarchical fusion model; Fan等人,2018)采取对故事内容的一句话描述,并产生一个段落。Plan-and-write(计划与写作)技术(Yao等人,2019)也采用了分成两级的方法。Plan-and-write系统并非去学习生成一个单一的在大体上描述情节的句子,而是学习生成一连串的关键词。然后,这些关键词中的每一个都被用来提示语言模型,使其产生关于该关键词的内容。如果关键词呈现出含义连贯的情节发展,那么更具体层次的阐述内容也会如此。PlotMachines(Rashkin等人,2020年)根据用户提供的一组概念短语来提示故事生成器。然而,系统不是将这组概念短语作为大纲来阐述,而是自己决定以何种顺序来引入这些概念。

另一种控制故事请走向的方法是提供故事中的关键情节点,然后让模型填写中间的部分。Wang, Durrett, and Erk (2020) 试图在故事的给定开头和给定结尾之间进行插补(interpolate)。然而,他们使用的语言模型不知道如何关注结尾的提示。相反,他们从开头的提示开始生成一些候选者,并使用一个重新排序器来判断整体的一致性(开头、中间和结尾),取其精华。Ippolito等人(2019)提出了一种内填法(in-filling approach),他们使用给定的故事开头和结尾,并生成可能在故事中间发现的关键词。然后,这些关键词被用来提示一个语言模型,生成故事的中间部分。
神经-符号性故事生成
基于神经网络的语言模型的一个问题是,神经网络(无论是递归神经网络还是transformer)的隐藏状态(hidden states)只代表了根据先前的上下文历史做出可能的词汇选择所需要的东西。神经网络的 "状态 "不太可能与读者正在构建的关于世界的心理模型相同,后者侧重于人物、物体、地点、目标和原因。从符号系统到神经语言模型的转变,将重点从读者的建模转移到语料库的建模。这是有道理的,因为故事语料库形式的数据是现成的,但读者形成的心理模型形式的数据却不是现成的。假设关于读者心理模型如何被符号化的理论是正确的,我们能否建立一种神经-符号系统,将神经语言模型的优势与符号模型的优势结合起来?基于神经网络的语言模型通过在语言而不是有限的符号空间中操作,给我们提供了对非常大的输入和输出空间的某种稳健性。但是基于神经语言模型的故事生成也导致了从故事含义的连贯性的角度来看的退步。另一方面,符号系统通过逻辑和图形约束在一致性方面表现出色,但其代价是有限的符号空间。
Lara Martin (学位论文, 2021)提议采用GPT-2这样的神经语言模型,并用因果关系的推理来约束它。GPT-2作为一个语言模型,可以根据先前的单词符号的历史,概率性地生成故事的后续。Martin的系统解析生成的后续,并使用VerbNet来推断读者对该句子的前提条件和影响会有什么认识。如果后续句子的前提条件没有得到故事中先前句子效果的支持,后续句子就被拒绝。如果前提条件得到支持,那么该句子的效果就被用来更新一套描述世界的类似逻辑的命题。这些命题之所以从VerbNet中提取,正是因为它们是基于读者从阅读句子中可以推断出的内容,可以被认为是一个简单的读者模型(reader model)。通过跟踪假设性的读者模型,这个系统不太可能以对读者没有意义的方式,从一个事件过渡到另一个事件。

CAST系统(Peng等人,2021年)做了与上述神经符号性生成系统类似的事情。
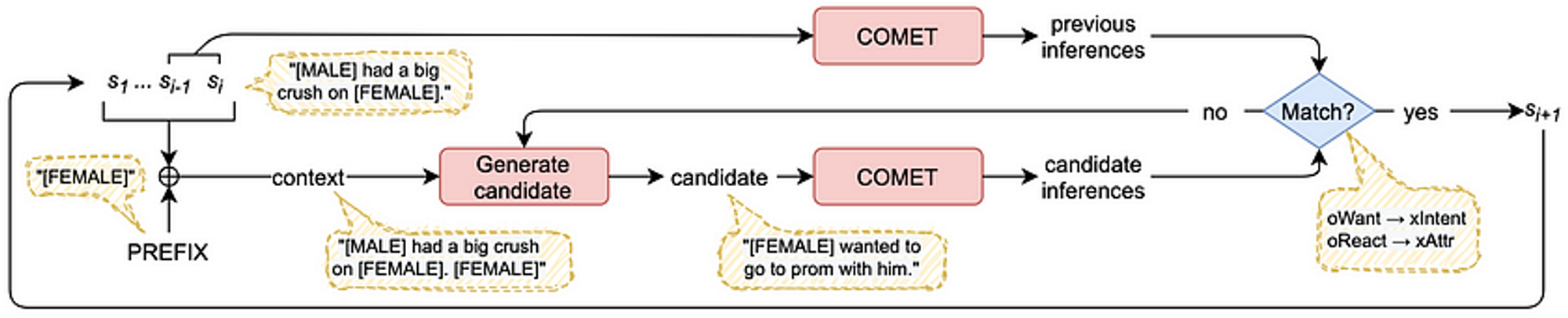
CAST使用COMET常识推理模型作为世界引擎。它推断出故事中人物的需求和愿望,并试图与之前事件中人物的需求和愿望相匹配。角色的目标和意图是读者追踪故事含义连贯性的另一种超越前提条件和效果的方式。
其他的基于神经网络的方法
从语言模型中直接采样故事的后续文本,并不是使用神经网络生成故事的唯一合理方式。人们可以想象类似于搜索的算法,将神经网络作为决策的资源。
很多故事都涉及常识性知识。常识性知识(commonsense knowledge),或者更具体地说,共享性知识,是指人们可以假设大多数人都持有的知识。为了创造一个对人类读者来说有意义的故事,利用常识性知识可能是有利的。像COMET和GLUCOSE这样的神经网络经过训练,可以接受输入的句子,并对人类可能推断的内容做出推断。C2PO系统(Ammanabrolu等人,2021年)接受一个起始事件和结束事件,并试图填补故事的中间部分。它没有使用语言模型,而是使用COMET来推断大多数人类可能认为在故事开始之后的下一步是什么,以及在故事结束之前可能出现什么。这个过程不断重复,创造出一个由合理的后继情节和前驱情节组成的有向无环图,直到找到一条从起点到终点的完整路径。
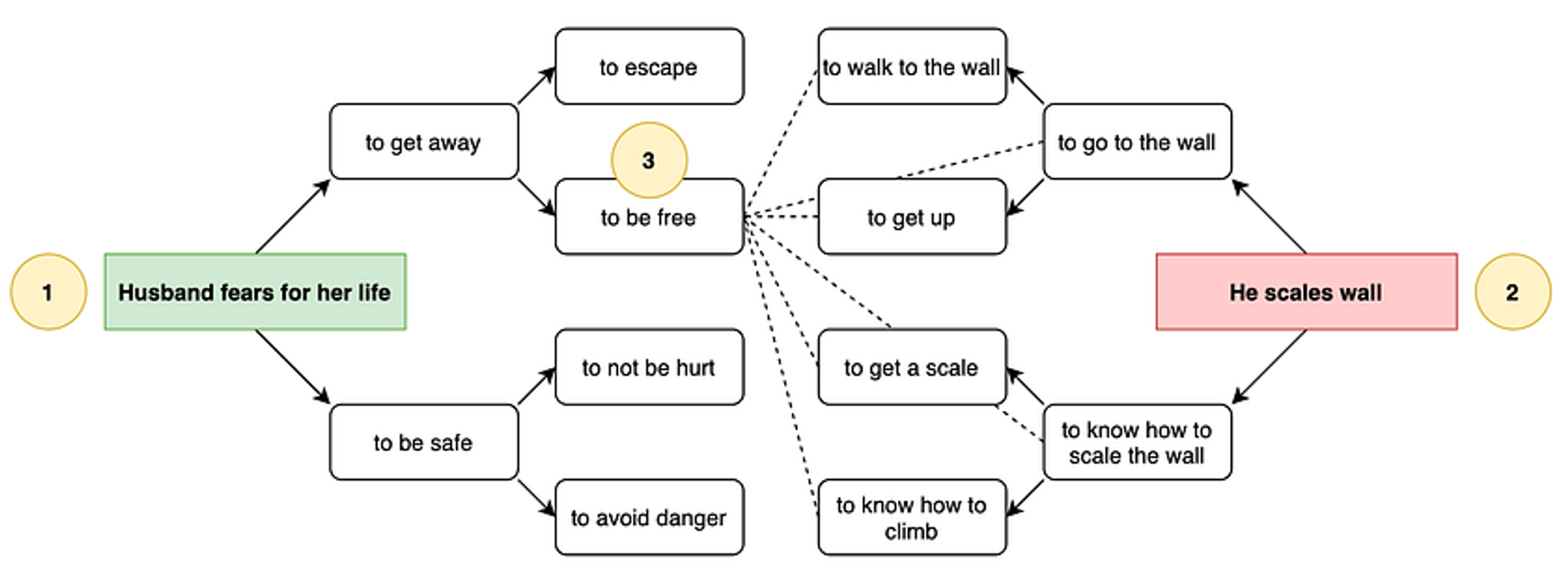

前面提到的关于叙事心理学的工作建立了故事含义连贯性(coherence)和问题回答(Question answering)的任务之间的联系。因此,故事生成的另一种方法是将语言模型作为一种资源来进行查询,以回答关于故事世界的问题——这些精心选择的问题的答案成为故事本身的内容。Castricato等人(在第三届叙事理解研讨会上)对此进行了探讨。他们从一个关于故事结局的句子开始,倒过来生成一个故事。他们生成一些关于故事如何达到这个结局的合理问题,训练一个能够生成解释的语言模型来回答这个问题,然后把生成的解释作为故事的前一段。然后他们用最后一个片段作为问题的来源,重复这个过程。从理论上讲,这样做的结果是使故事在含义上更加连贯,因为每一个添加到故事中的片段都会解释接下来的内容。
结论
自动故事生成这个领域经历了许多阶段性转变,也许没有比从非机器学习型故事生成系统到基于机器学习的故事生成系统(尤其是神经网络)的阶段性转变更重要的了。符号化的故事生成系统能够生成合理的长而含义连贯的故事。这些系统的能力主要来自于良好的知识库。但这些知识库必须用手来构建,这限制了系统所能产生的内容。当我们转向神经网络时,我们获得了神经网络的力量,可以从语料库中获取和利用知识。突然间,我们能够在故事生成系统中生成更大的故事空间并涉及更多的主题。但是,我们也抛开了很多关于读者心理和推理丰富知识结构以实现故事含义连贯性的能力。即使增加神经网络语言模型的规模,也只是推迟了神经网络生成的故事中不可避免的前后一致性的崩溃。
像这样的入门材料使我们更容易记住以前走过的路,以防我们把婴儿和洗澡水一起扔出去。这并不是说不应该追求基于机器学习或神经网络的方法。如果有退步,那是因为这样做给了我们一个强大的新工具,有可能带我们走得更远。在自动化故事生成方面工作的令人兴奋之处在于,我们确实不知道前进的最佳路径。有很多新想法的空间。