大数据语言模型与程序化叙事生成(上)
聊聊出现在2018年之后的基于深度神经网络预训练语言模型的故事生成技术。由于内容篇幅较长,会分成上、下两个部分,本篇先跟大家介绍语言模型的基本原理和在写作上的表现。

前言
2018年,我写了一篇关于使用AI来自动生成叙事的文章:故事工程学:人工智能与程序化叙事生成。这篇文章整理了“过程式叙事生成(Procedural Narrative Generation)”这个领域的各种自动生成故事的方法。
当时的文章虽然使用的是AI这个词,其具体涵盖的技术却跟今天大行其道的GPT,BERT等完全不是一回事。那时的人们还在精心定义可能的故事情节所组成的空间(故事域; story domain),研究如何随机在这个空间中采样的同时,保证采样得到的情节符合逻辑情理和人物设定、能够表达作者想要表达的内容、甚至还能促成一些连开发者都预料不到的精彩情节的产生。
而随着像GPT这样的大规模预训练语言模型的流行,像AI Dungeon和Chat GPT这样对公众开放的服务的出现,人们也看到了故事生成的全新的可能性——我们可以完全不去定义故事域、不去费劲地告诉计算机怎样算是符合逻辑清理和人物设定,而直接跟计算机用含糊而模棱两可的自然语言对话,告诉它我们想要什么样的故事,然后期待在几千亿单词的语料库上训练过的拥有几千亿参数的神经网络,能给出什么样的惊喜。
今天,我就想来聊聊出现在2018年之后的这些基于深度神经网络预训练语言模型的故事生成技术。在感叹于这些技术之神奇的同时,也来谈谈在前一篇文章中所介绍的那些2018年以前的技术,为什么也还远远不能被取代。由于内容篇幅较长,会分成上、下两个部分,下面的第一部分会先跟大家介绍语言模型的基本原理和在写作上的表现。
深度学习和语言模型
2018年,谷歌首次提出了神经网络架构Transformer [3],在深度神经网络中大规模使用自注意力(Self-attention)机制,飞跃性地提升了语言模型考虑上下文的能力,从此将基于深度神经网络的语言模型推向了一个全新的高度。
语言模型的本质是数学统计模型,就像大多数机器学习方法中使用的模型,它有数量庞大的参数,来拟合给定的训练数据中的输入-输出关系。为了训练出对人类语言有基本认知的语言模型,需要有庞大的语料库(Corpus)。比如GPT-3的训练数据包含多达4990亿的单词,其中包括网站原始文本数据、维基百科、书本、论坛问答等等。
被训练的模型通过玩一些基本的文字游戏来逐步掌握语言的用法。比如GPT在训练中就要玩文字接龙的游戏:每次从语料库中随机抽取一段话,从某个位置截断分为前半部分和后半部分。把前半部分输入到模型中,就能得到一个条件概率分布——给定输入的前半部分,所有可能的后续的概率是多少——再从这个概率分布中取样,就得到一个模型生成的后半部分。将这个机器生成的后半部分和语料库中的后半部分比较,根据比较结果来调整模型的参数,使得模型更倾向于生成语料库中的后半部分。
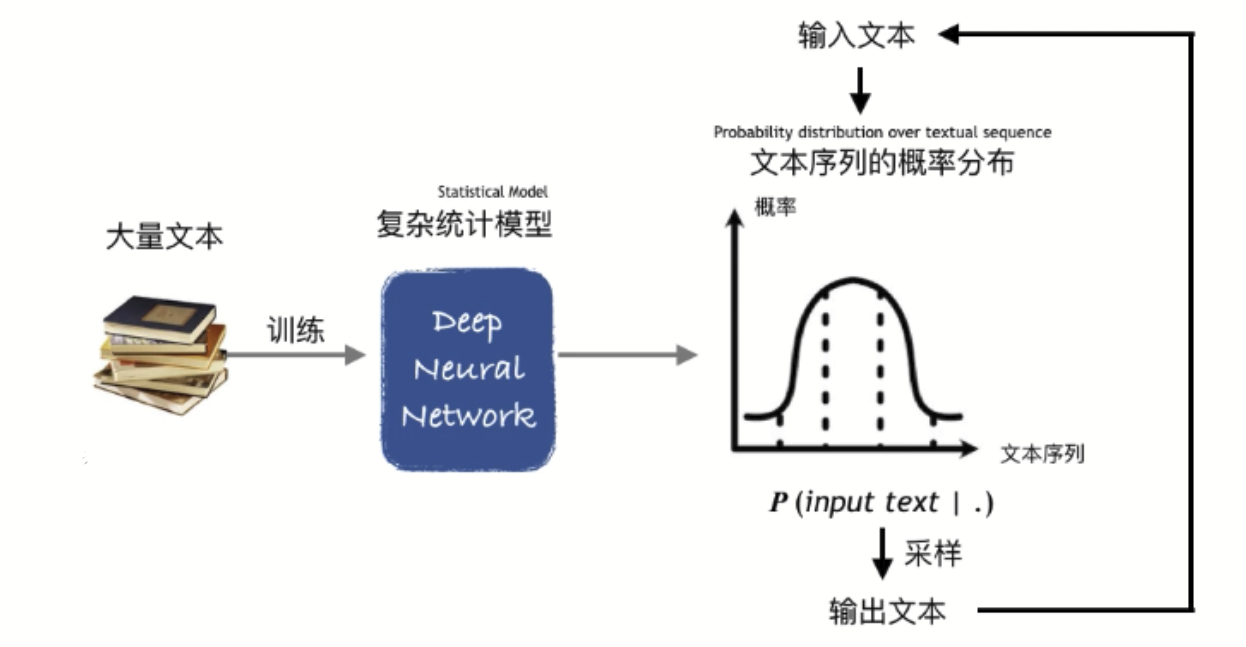
实际操作中模型并不是一下就输出整个后半部分,而是每次输出一个字/单词,再将输出的字/单词追加到输入中,再次输入得到下一个字/单词,如此反复直到全部的后半部分都输出完毕。由于这个过程向模型输入了一个字或单词组成的序列,输出也是一个字或单词组成的序列,我们将这种模型称为“Sequence-to-sequence model(从序列到序列的模型)”。

这个训练过程,乍一看只是在盲目地模仿训练语料库。事实上,这种说法并不完全准确。语言模型是一种深度神经网络(deep neural network),是由多层的“神经元”计算模块组成的复杂数学计算函数,包含了数量庞大的参数用于拟合数据。与传统的机器学习不同,深度学习不仅要用统计模型去“学习”输入中的特征和输出中的特征之间的关系,还要“学习”这些特征本身。也就是说,深度学习的输入往往是原始对象的数据表示(比如一段文字),一个深度神经网络要首先从原始对象中提取出对计算任务有用的特征,才能去完成计算任务。
这些特征往往是比原始的输入数据本身抽象层次更高的信息。比如,看到下面这句话
“我们看完这部电影的结局仍然意犹未尽,一直呆呆坐着等到工作人员名单播完都没有离开电影院”
仅凭字面意思,很难得出结论说这是对电影的积极评价。只有先在脑海中想象出这句话所描述的事件,将这个事件联系到一个典型的电影入迷者的形象,才能进一步得出这样的结论。
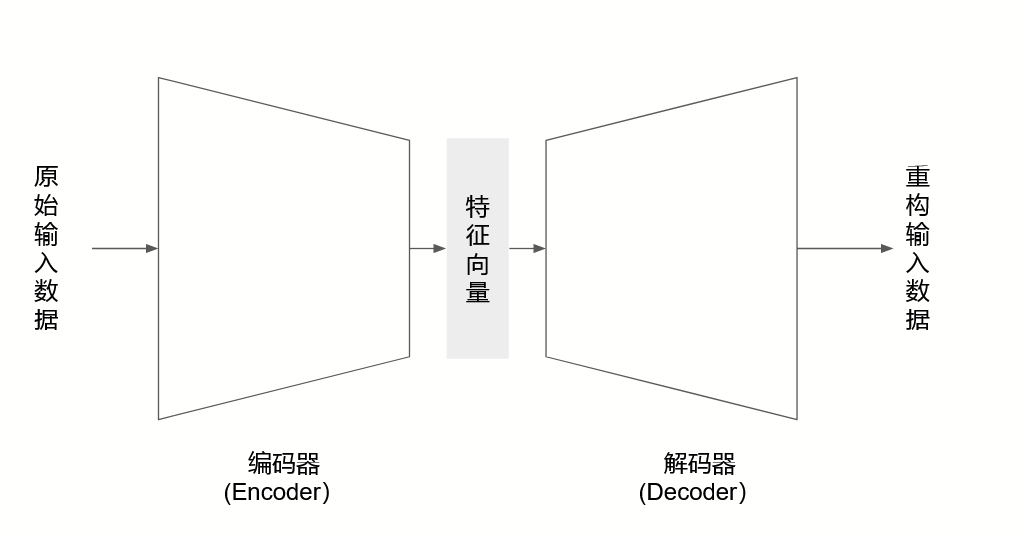
深度神经网路有别于传统的机器学习模型的一个很重要的地方,就在于它有能力去进行这样的抽象。基于Transformer的语言模型具有一种“编码器-解码器(Encoder-decoder)”结构,首先用编码器将高维空间中的原始数据用低维的特征向量来表示(也就是AI从业者们常说的“Embedding”),再通过用解码器根据这些特征向量还原(reconstruct)出原始数据的方式来验证这些低维的特征向量有足够的信息来代表对应的原始数据。这些低维的特征向量大多数情况下并不会直接对应于人脑中的那些抽象概念(比如”电影入迷者“),但它们用更简洁更一般的方式概括了原始数据,在这种意义上可以被理解为是一种机器形成的抽象概念。
因此语言模型在完成了足够大量的这种文字接龙训练之后,某种意义上它也形成了一整套建基于语言之上的抽象概念——也就是说,某种意义上,它也形成了它自己的对语言的理解。
这样训练出来的语言模型具有基本的语言能力,也就是说出来的话看起来都像人话的能力。但对于具体的任务来说,这样的能力还远远不够。一个段落概述AI需要知道什么样的句子才是好的概述,一个聊天机器人AI需要知道什么样的回答对对方来说才是好的回答,一个故事生成AI得知道什么样的文本才代表一个好故事,等等等等。
为了能够使得语言模型在基本的语言能力基础上还能胜任具体的任务,就要进行下一阶段的训练,也就是微调(Fine-tuning)。这个阶段的训练往往需要借助具体任务相关的有标记的数据集(labeled data),其中包含一系列具体任务相关的输出,以及每个输出对应的好坏评估。
最近大火的Chat GPT,则进一步采用了强化学习(Reinforcement Learning)的方式来进行这一阶段的训练。OpenAI采用大量人力来审查一个GPT-3模型的输出,就这个输出针对给定的输入对话是否有用来打分。这些打分数据又被用来训练一个同样基于神经网络的自动评分模型。有了这个自动评分模型之后,就能在人工打分没有覆盖到的更大的范围内给模型输出提供反馈,利用这些反馈来对模型参数进行微调,使得模型在具备基本的语言能力的基础上,还能输出作为聊天机器人更希望被看到说出的话,让语言模型从“盲目地模仿人类说话”到“有目的地说话”走出第一步。
语言模型的写作能力
回到我们的主题,这样训练出来的语言模型,实际的写作能力如何呢?
在今年发表的一篇论文《对Transformer深度神经网络的创意写作能力的系统性评估(A Systematic Evaluation of the Creative Writing Skills of Transformer Deep Neural Networks)》[1] 中,作者Marco等人就这个问题进行了一次实验。
实验中,论文作者们随机选取了几十个电影标题(这些电影被要求足够冷门, 从而大多数人都没看过),让一个经过微调(fine-tuning)的Transformer语言模型根据这些标题生成故事梗概。比如,如果给定标题是“The Roommates (室友)”,语言模型可能会生成下面的虚构的剧情梗概:
The Roommates tells the story of a group of college roommates who live together in a small apartment in Los Angeles, California. The film follows the lives of the roommates as they struggle to cope with the pressures of college life and the changes that come with it.
电影《室友》讲了关于一群大学室友的故事。这群大学室友一起住在加州洛杉矶的一个小公寓里。电影追踪了这些室友们在大学生活的压力面前随之而来的人生转变。
收集到这些生成的电影剧情梗概之后,作者们请到了六十多名英语流利的硕士生作为调查受试者。每个受试者会被分配到一个电影标题和这个标题的两段剧情梗概——一段是电影原来的真实剧情梗概(由人类作家完成),另一段则是语言模型生成的剧情梗概,受试者打分时并不知道文本段落的作者是谁。受试者要在文法通顺性(Readability)、可理解性(Understandability)、标题相关性(Relevance)、信息丰富性(Informativity)、吸引力(Attractiveness)和创意性(Creativity)六个方面给这些剧情梗概打分。结果可以说很出人意料:Transformer所生成的剧情故事梗概,除了在创意性上略低于人类(-3%),在所有其他方面的打分都要高于人类写作的版本。
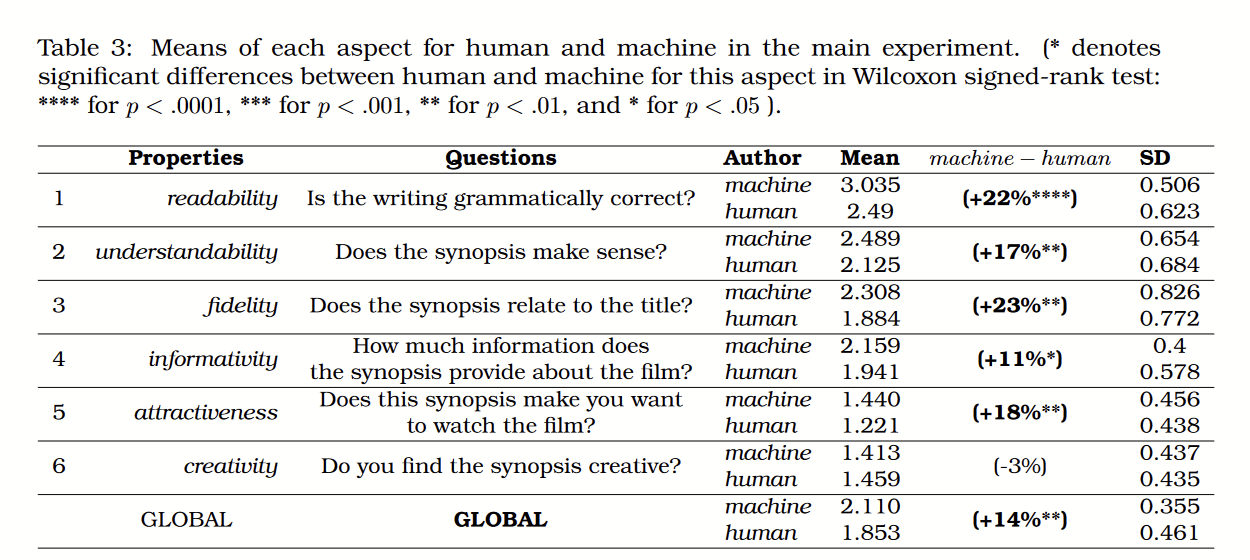
需要说明的是,上面的结果是针对平均评分来说的。而相较于人类作品水平的参差不齐,Transformer输出的文本质量较为稳定。在不少指标上,人类作品得分是被那些质量非常差的作品拉低了。
上面的打分是在受试者并不知道读到的两段文本作者分别是谁的情况下得到的。在第二组实验中,受试者打分前就知道两段文本分别是机器还是人类写的。结果在这组实验最后得到的得分中,机器生成的文本在所有评分指标上的得分都比第一组实验降低了。第一组实验中,机器文本平均比人类文本得分高0.257,而在第二组实验中,机器文本平均只比人类文本得分高0.107。而人类文本的得分,在第一组实验和第二组实验中则没有明显差别。
这似乎意味着对人类文本质量的认知是受试者评分的基准,而当受试者知道文本是机器生成时,它们的评估变得更加严格了。这个现象可以由一个日常经验中得到解释:当我们看到一段文本中出现了似乎不太对劲的内容,如果我们知道作者是人类,通常的反应会是去思考作者的意思,帮作者去解释看似不对劲的内容为什么其实是合理的;而如果我们知道作者是机器,通常的反应则会是认为这是机器出错了。
除此之外,作者们也指出机器生成的故事梗概的一些其他共同特征,比如它们通常比较套路化,使用诸如“这个电影讲了这样一个故事(The film tells the story…)”这样的模板式句子,而且平均长度比较一致,都是4-5个句子。语言模型生成的故事梗概有时会犯事实性的错误,比如下面这个例子:
English: An Autumn in London tells the story of a group of English students who are invited to spend a weekend at a country house in the English countryside. The film is set in the late 1920s and early 1930s, during the English Civil War. The main character is a young Englishman who has been sent to London to complete his education. He meets a young woman who is also studying in London and falls in love with her. However, she is engaged to be married to the son of a local aristocrat.
电影《英国:在伦敦的一个秋天》讲述了一群受邀在英国乡下一间别墅度过一个周末的英国学生的故事。故事发生在20世纪20年代晚期到30年代早期,也就是英国内战期间。主人公是一个到伦敦完成教育的年轻的英国人。他遇到了一个同样在伦敦学习的年轻女人并与对方坠入爱河。然后,对方其实已经跟一个当地的贵族儿子订婚了。
文中提到的英国内战实际上发生在17世纪,远远早于20世纪。
机器生成的文本有时会因为出乎意料的展开而带来戏剧性效果:
The film Beware Of Pickpockets tells the story of a group of pickpockets who are on the run from the police. The film is set in a small town in the south of France during the early 1970s. The main character is a pickpocket named Jean-Claude, who lives with his widowed mother, who works as a waitress in a restaurant, and his younger brother, Jean-Michel, who is a student at the local high school. The two brothers are in love with the same girl, Marie, but she is engaged to the son of a wealthy family, and the father does not approve of their relationship because he fears that he will lose his job if he marries her. Jean and Michel’s relationship is further complicated by the fact that Marie’s father is a member of the pickpocket gang, and he is also the leader of the gang.
电影《小心扒手》讲了一群正在警察追踪下逃亡的扒手的故事。故事发生在20世纪70年代法国南部的一个小镇。主人公是一个名叫简-克劳德的扒手。他跟他的在饭店当服务员的寡妇母亲住在一起。他的弟弟简-迈克尔是当地的一个高中生。两兄弟爱上了同一个女孩玛丽。但是玛丽已经与一个有钱人家的儿子订婚了。而且父亲并不同意他们的婚事,因为他害怕他会因为他们的婚姻而失去工作。简和迈克尔的关系还更复杂:因为玛丽的父亲其实也是扒手帮的成员和领导,
机器生成的文本有时也会自相矛盾,比如下面的例子:
Abby Sen is a young woman who lives with her widowed mother in a small town in the American Southwest. Abby’s father died when she was very young, and her mother has since remarried and has a daughter named Abby.
艾比·森是一个年轻女人,跟她的母亲一起住在美州西南部的一个小镇。艾比的父亲在她很小的时候就去世了。之后艾比的母亲再次结婚,并生下一个女儿叫做艾比。
这段文本在艾比的父亲究竟是谁上自相矛盾了。
这里介绍的论文专注于为影片标题生成故事梗概的任务。影片的故事梗概通常比较短小。而在需要更长的文本的任务中,内容的前后一致就变成了更加严重的问题。
比如,在同样基于Transformer模型的AI Dungeon(https://play.aidungeon.io)游戏中,语言模型要对玩家输入的用自然语言描述的任何动作指令给出反馈,塑造出一种仿佛在玩传统文字冒险游戏的感觉。下面是一个例子(玩家输入为粗斜体):
> You're walking down the dark city streets while neon lights flash brightly above you. As you pass an alley you see a strange man hunched over something on the ground. He jumps up and down and points frantically, saying something you can't understand. His eyes are wild and they are locked right on you.
(你沿着昏暗的城市街道一路走下去,霓虹灯在你头顶明亮地闪烁。正当你穿过一条小巷时,你看到一个奇怪的男人在地上的什么东西面前弯腰俯身。他像发神经一样上蹿下跳,指指点点地说着一些你听不懂的东西。他狂野的视线紧紧锁在你身上。)
> You greeted him with Donald duck voice.
(你用唐老鸭的声音跟他打了招呼)
> You duck down and wave your hand in a "friendly" manner. The man stares at you and begins to laugh. He then hits your arm with the stick he is holding.
(你躲开并“友好地”招手。这个男人盯着你看并开始大笑起来。然后他用他的手杖击打了一下你的手臂。)
在传统的文字冒险游戏中,玩家同样输入文字指令与游戏系统互动 ,但这些指令必须来自游戏开发者预先定义好的指令集,否则就只会得到诸如”您输入的指令无效“这样的回答。因此玩家在玩的过程中多少要去猜测游戏开发者的意图,而且虽然面对的是一个能输入任何文本的界面,实际还是被游戏开发者所限制,有时候的体验会非常令人沮丧。
使用语言模型来代替这种预定义的指令系统,终于让玩家真正意义上地能够在文本框中输入任何文本。而且就像是在跟一个人类游戏主持人对话一样,不论你对对方说什么,对方总能回答几句,不会只给出一句冰冷的“指令无效”,甚至有时候通过刁钻的输入还能引导对方说出相当精彩的回答。
但是反过来,在传统的文字冒险游戏中,是存在一个虚拟的游戏世界实实在在地以数据和程序的形式运作着的。玩家尽管通过文本指令与系统交流,最后实际上是在与这个虚拟世界互动。这个虚拟世界中存在着前后一致的地图、物品和NPC,玩家在这个虚拟世界中所克服的也是实实在在的挑战,解决的是实实在在的谜题。
而到了AI Dungeon这里,一切都只存在于语言层面。AI所说出来的话背后没有任何数据和程序层面的对应物,只是空洞的文本。如果这些文本有任何语义上的内容,大概只存在于玩家自己的脑补中。
比如,在一次AI Dungeon中我与DM有这样的对话记录(我输入的文本为斜体):
> (The elves) point down the street and tell you the name of the inn. You thank them and enter. When you walk in, you see that it is a small inn, but they serve good food and you can see a few elves enjoying a drink at a nearby table.
(精灵们沿着这条街指过去并告诉了你旅馆的名字。你感谢了她们并进入了旅馆。当你进入的时候,你看到这是一个很小的旅馆,但是他们提供很棒的食物,你看到不少精灵在附近的桌子上享受饮品。)
> I step out of the inn.(我走出了旅馆)
> Outside you notice a group of elves playing a game. They look like they are enjoying themselves. You wonder if you could join the game.
(在外面你看到了一群精灵在玩一个游戏。她们看起来很享受。你在想你是不也能加入她们一起玩。)
> I step back into the inn. (我又走回了旅馆里)
> You walk up to the front desk. A man is standing there looking bored. "I was wondering when you would get here," he tells you.
(旅馆的护卫举起了武器。你用剑杀死了前两个护卫。第三个护卫注意到了你的武器)
> I step out of the inn.(我走出了旅馆)
> You are now outside. You notice several guards in the courtyard. They seem tense. They are all keeping an eye on some area behind you.
(你现在在旅馆外面。你注意到庭院里有几个守卫。他们看起来很紧张。他们都盯着你后面的某个位置看。)
> I steped back into the inn.(我又走回了旅馆里)
>You walk up to the front desk. A man is standing there looking bored. "I was wondering when you would get here," he tells you.
(你走向前台。一个男人看起来百无聊赖地站在那里。“我正想着你什么时候来呢。”)
我发现我每一次走进旅馆,这个旅馆都好像变成了一个完全不一样的地方,我找不到原来的NPC和物品,我之前在旅馆做的事情到了再次进入旅馆的时候也没有后续。
作为游戏文本的读者,我在阅读的过程中会形成一个关于这个游戏世界是什么样的脑内模型(Mental Model)。人们对传统意义上的“玩游戏”这件事的理解是利用游戏机制在一个游戏世界内达成某个目标。正是通过这个脑内模型,我才能够预测自己在游戏世界内的行动会有什么结果,从而为达成自己的目标指定一系列行动计划。
然而在AI Dungeon中,我通过脑内模型做出的判断不太可能在游戏中得到应验。甚至很多时候因为游戏主持人前后不一致的说辞,这个脑内模型都很难建立起来。我也就很难获得上面所说的这种传统的“玩游戏”体验。
值得注意的是,当人在读一段文本时,如果没有对机器生成的文本有很强的偏见,就容易产生ELIZA效应,潜意识地去构想出文本背后存在着一个人格在述说这一切,从而解读出许多文本中并不存在的内容。因此AI事实上并不需要做到100%的前后一致,就足以在这类游戏中让人产生沉浸感。
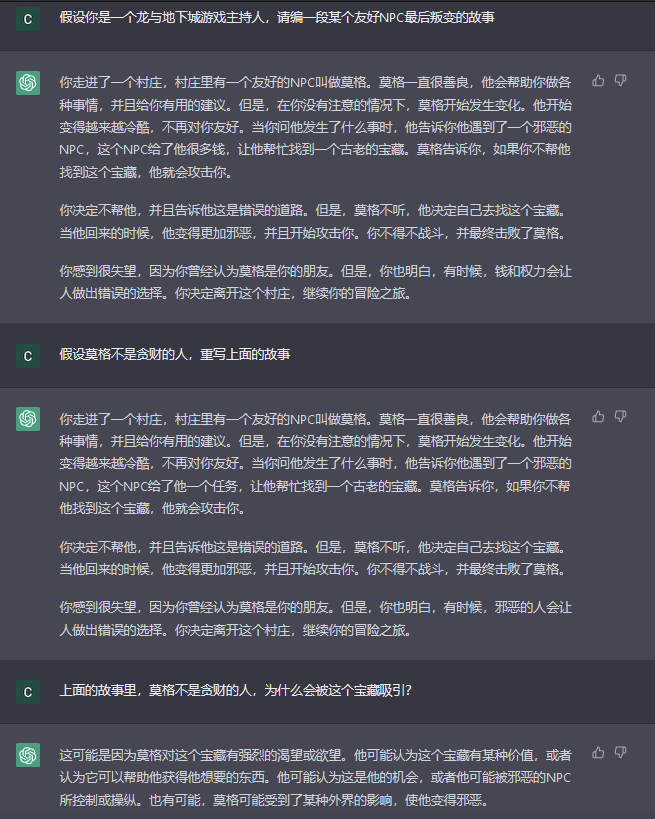
我的友人起司在开放世界游戏Delysium [6]的玩家社群中,运营过一个由chatbot驱动的文字冒险游戏。玩家要跟一个由语言模型控制的AI人物David对话,并帮助他做出一些重要决策。在运营这个游戏的过程中起司发现,尽管David经常会说一些前后不一致的话,玩家却并没有因此而出戏,反而将这种前后不一致解读为“David还不完全信任我”。
总结
至此,我们讨论了语言模型的基本原理,了解到它的本质仍是基于大数据的复杂统计模型,通过拟合训练数据来起作用。但深度神经网络的架构和Transformer的自注意力机制,让它并不单纯是模仿训练数据最原始的样子,而具有一定的抽象和概念重组的能力。
语言模型生成文本的原理是在这个统计模型所定义的文本序列概率分布中依序采样。在经过最基础的模型训练后,语言模型只能输出看起来像人话的文本。但在经过后续的微调(Fine-tuning)之后,能够有一定“目的性”地说话。
有关Transformer的调查展示,Transformer生成的短故事文本似乎已经能够在文法通顺性(Readability)、可理解性(Understandability)、标题相关性(Relevance)、信息丰富性(Informativity)、吸引力(Attractiveness)这几个方面都至少达到人类的平均水平。但它所生成的文本仍然会存在事实性错误和前后不一致。
而读到这里,很多疑问会顺理成章地冒出来。比如,如果真的使用这样的AI生成故事,该怎样控制故事内容的走向?又有没有可能用一种巧妙的方式来使用这些AI来改善它前后不一致的问题?基于语言模型的故事生成,与较为传统的故事生成方法之间又是什么样的关系?
我们会在下篇中讨论这些问题。
参考文献
[1] Marco, Guillermo and Gonzalo, Julio and Rello, Luz, A Systematic Evaluation of the Creative Writing Skills of Transformer Deep Neural Networks (February 24, 2022). Available at SSRN: https://ssrn.com/abstract=4042578 or http://dx.doi.org/10.2139/ssrn.4042578
[2] Playing With Unicorns: AI Dungeon and Citizen NLP: http://digitalhumanities.org/dhq/vol/14/4/000533/000533.html
[3] Vaswani, Ashish, Noam, Shazeer, Niki, Parmar, Jakob, Uszkoreit, Llion, Jones, Aidan N., Gomez, Lukasz, Kaiser, and Illia, Polosukhin. "Attention Is All You Need." (2017).
[4] Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S. Language models are few-shot learners. Advances in neural information processing systems. 2020;33:1877-901.
[5] Hung-yi Lee, Chat GPT (可能)是怎麼煉成的 - GPT 社會化的過程:https://www.youtube.com/watch?v=e0aKI2GGZNg&ab_channel=Hung-yiLee
[6] Delysium: https://twitter.com/The_Delysium; Chatbot David: https://twitter.com/sunyuqian1997/status/1587056660496908288