计算创意学系列(五):创作过程与创造力
欢迎来到计算创意学系列第五章,在上一章中,我们提出了如何以与底层机理无关的标准去评判一个系统是不是具有创造力的问题,从“能够产生有价值的新事物”这个简单的认识出发,探讨了如何评估一个创造力系统的价值和新颖性。 除了对算法输出有要求,一个算法要被称作是“有创造力的”,似乎算法本身还需要具有一些其他的特性。 这一章,我们就来看看,创作过程的什么特性被认为是具有创造力的,这些特性又如何能够在算法中实现。

欢迎来到计算创意学系列第五章,在上一章中,我们提出了如何以与底层机理无关的标准去评判一个系统是不是具有创造力的问题,从“能够产生有价值的新事物”这个简单的认识出发,探讨了如何评估一个创造力系统的价值和新颖性。
既然要与系统的底层机理无关,就要将系统看作是一个黑盒子,单纯基于它的输出去做评估。价值和新颖性都是对创造力系统的输出进行的评价。在上一章最后,我们提到了仅仅以一个系统的输出作为参考,是不足以判定这个系统是否具有创造力的。
想像有一天你在美术馆参观,看到了下面这样一幅画:

你觉得很有意思,就去问这幅画的作者这是在表达什么。想像作者可能的两种回答:
(1) “这幅画描绘的是我的朋友们。画上的每一个点都代表了我的一个朋友,点的大小代表了我跟这个朋友的熟识程度,点的颜色代表了我对这个朋友的感觉”;
(2)“这幅画没什么含义,我就是随便画了一些大小不一样的圆形。”
在听到这两种回答的情况下,你还能对这幅画的艺术价值作出一样的评价吗?大多数人给出的答案是否定的。这意味着,决定人们对一件作品的价值的判断的,不仅仅是这件作品本身,还包括这件作品被创作出来的过程。
也就是说,除了对算法输出有要求,一个算法要被称作是“有创造力的”,似乎算法本身还需要具有一些其他的特性。
这一章,我们就来看看,创作过程的什么特性被认为是具有创造力的,这些特性又如何能够在算法中实现。
DARCI系统:意向性和自主性
我们先来考察一个声称在创作过程中体现出了创造力的人工智能系统。
DARCI(Digital ARtist Communicating Intention)系统最初在2010年的一篇论文《在一个创造力系统中实现鉴赏力(Establishing Appreciation in a Creative System)》[6] 中被提出,是一个图像生成系统。与大部分同类的系统不一样(比如第三章中介绍过的Deep Dream和Deep Style),DARCI系统的设计从一开始就是以”在算法中展示出创造力“为目的。
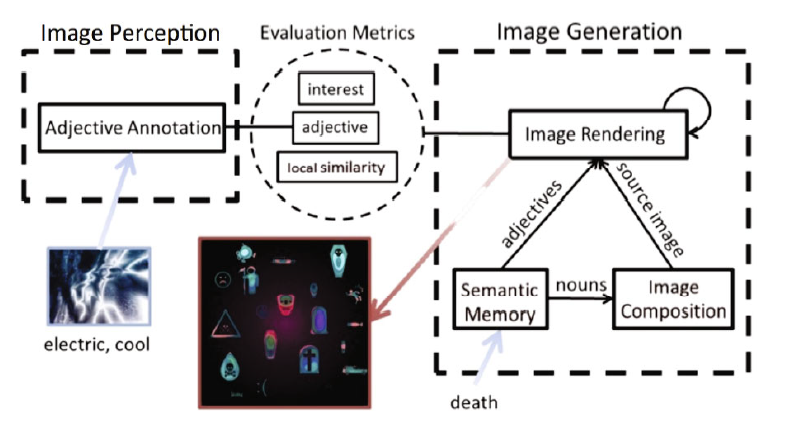
DARCI系统的图像生成模块接受一个名词所表达的概念作为输入,能够生成一幅表达这个概念的全新图像作为输出。根据DARCI系统的开发者们,能够在输入概念的指导之下去生成一个能够传达这个概念的图像——这体现了创作过程的意向性(Intentionality);另一方面,DARCI系统能够生成的图像具有丰富的可能性,能创作出用户难以预测的全新图像——这体现了创作过程的自主性(Autonomy)。

DARCI系统的一个重要组成部分是一个图像认知模块。图像认知模块接收任意图像作为输入,能够去尝试“理解”这幅图像想要传达的含义,并用一些形容词来表示这个含义。
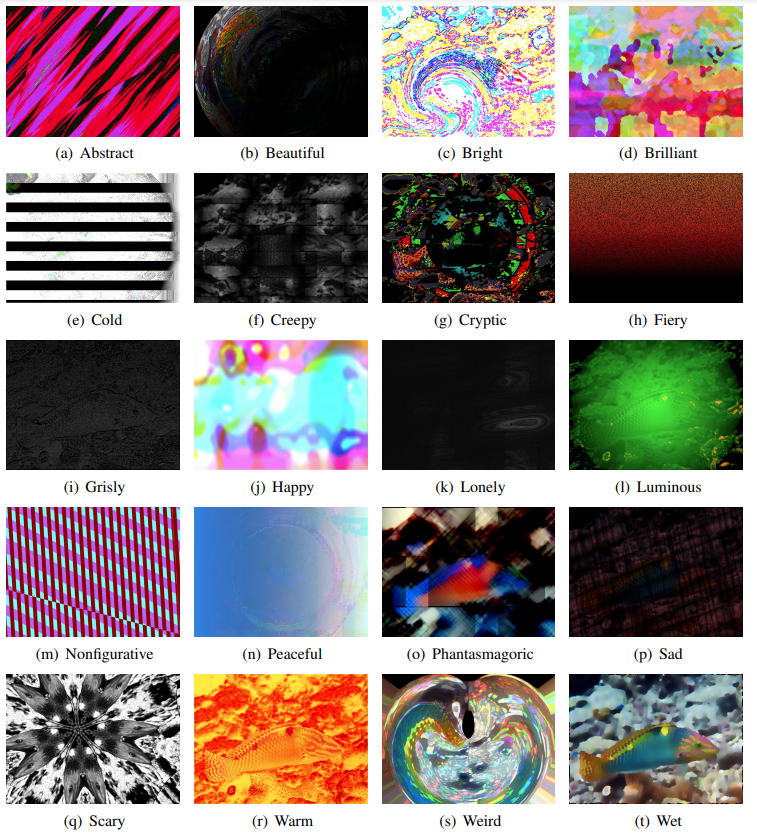
图像认知模块对输入图像中含义的提取,是通过一系列神经网络(Neural Network)从训练数据中建立起图像的视觉特征和一组用来表达图像含义(Semantics)的单词之间的统计关联。这些视觉特征包括色彩情感、饱和度、点线面的分布、线条的方向统计等等51个底层的图像特征。而用来表达图像含义的单词是大量形容词,包括“荒谬的(bizarre)”、“血腥的(bloody)”、“孤独的(lonely)”等等。
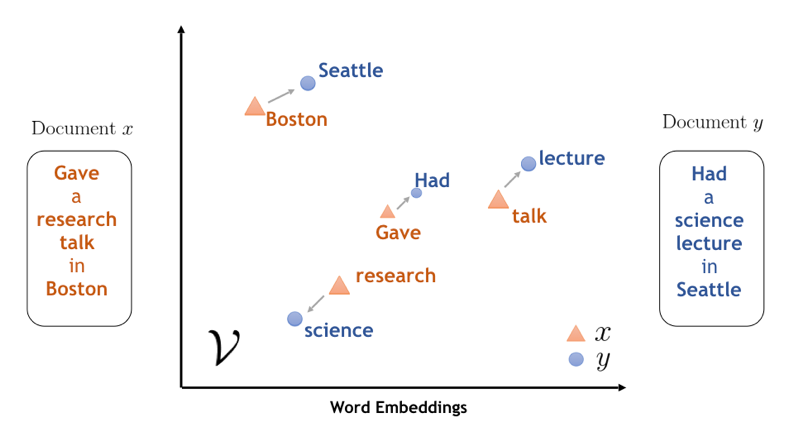
DARCI系统的图像认知模块使用了自然语言处理领域的一些语义模型技术,包括语义网络(Semantic Network)和语言的向量空间模型(Word Embedding),使得它对图像含义的认知能够不被限制在出现在训练数据集中的数量有限的单词中。比如说,尽管训练数据中没有出现“奇怪的(Strange)“这个词,但通过语义模型技术,DARCI系统能够知道”奇怪的(Strange)“这个词的意思跟”荒谬的(bizarre)“是相近的。
DARCI系统将图像的生成任务分为两个部分:1)确定图像的内容,以及 2)确定图像的风格。
图像的生成再次利用了语义模型技术。给定一个表示新图像主题的概念,DARCI会首先利用语义模型找到与这个概念含义相关的15个名词和形容词。比如,如果给定的概念是“战争”,语义模型模型可能会首先将这个概念分解为名词“士兵”、“军队”、“冲突”、“战斗”和形容词“血腥的”、“暴力的”、“孤独的”等等。这些名词和形容词分别用来指导新图像内容和风格的确定。
DARCI系统拥有一套图像内容库,其中存放了大量名词和可用来表示这些名词的简单图像。对选中的15个单词中的名词,DARCI会为每一个名词随机选择一个它所对应的1~2个简单图像加入到图像内容中。在构图方面,DARCI系统会根据简单图像所对应的名词与主题概念关联的强度来确定这个简单图像对应的内容在新图像中应该占多大视觉比例。这样,图像的基本内容就确定下来了。
图像风格的确定上再次使用了我们在前面几章多次提到的遗传算法(Genetic Algorithm)。遗传算法(Genetic Algorithm)是面对庞大搜索空间时的一种搜索策略,模仿达尔文进化论所描述的生物进化过程,将搜索空间中的每一个可能的解都看作是一个生物个体,各自有独一无二的基因型(Genotype),在其作用下演化出各种各样的表现型(Phenotype);遗传算法进而引入适应函数(Fitness Function)来模拟生物界的优胜劣汰——适应函数是以个体的表现型为自变量的函数,遗传算法会选择出那些表现型代入适应函数之后取值较高的解,对这些解进行某种形式的“融合”得到下一代的解(模拟生物交配),再用适应函数去评估这些下一代的解,如此重复一定迭代次数之后,将最新一代的解看作是目前计算资源下能找到的近似最优解。
DARCI系统内建了一套图像滤镜(Filter)库。最终图像的风格,取决于使用哪些滤镜和这些滤镜的参数——由于这里存在大量的可能性,因此采用遗传算法来进行更有效率的搜索。基因型(Genotype)被定义为所使用的滤镜和这些滤镜的参数,表现型(Phenotype)则被定义为应用了这些滤镜之后最终得到的图片。
为了定义适应函数(Fitness Function),DARCI系统会在遗传算法中每一次得到的图像上运行前面介绍过的图像认知模块,来得到一个分数评估每一个图像在多大程度上能够表达15个单词中的那些形容词。图像生成算法最后会返回这个搜索过程中得到的得分最高的图像。
我们可以看到,DARCI系统的图像创作过程,不是像许多同类系统那样(尤其是大多是基于深度神经网络的图像生成系统)只是“盲目”地生成一个图像,而确确实实存在一个“用作品来表达某种意图”的过程。不仅如此,DARCI系统的创作意图,由于表示成为了人类自然语言中的名词和形容词,还是完全能够被人类所理解的——甚至进一步,它还能够从这些名词和形容词的角度去解释人类的图像作品背后的意图,以这种方式完成了创作意图的沟通闭环。
按照DARCI系统的开发者们的说法,这正是一个人工创造力系统表达出意向性(Intentionality)的关键。首先,这个系统要具有一定程度的解释能力,可以用与它的作品的观众相通的语言来解释作品背后的创作“思路”。其次,这个系统不能完全是一个黑盒子,它至少要具有某种程度的透明性,让人们能够理解它的创作“思路”和它的输出之间确实是有正相关关系的。
DARCI的开发者们认为,因为艺术作品的欣赏,本质上是一种“共情(Empathy)”,需要作品在观众的内部激起了某种在作者的内部也发生过的事情,才能实现——因此创作过程的意向性是实现这种欣赏必不可少的。
另一方面,DARCI系统生成了跟输入图像不一样的新图像。由于DARCI系统所使用的庞大的语义模型、图像内容库和图像滤镜库之间复杂的组合爆炸效应,使得最终的新图像具有相当多的可能性,已经足以达到难以预测的程度——这成为了DARCI系统可以被看作是具有一定程度的想象力(Imagination)的论据。虽然DARCI系统接受输入,但输出和输入之间的关联性,在这种”想象力“的作用下,已经远远不是一种决定性的关联性。大量的与用户输入无关、DARCI系统内部的因素在左右着输出会是什么样子——DARCI系统在这种意义上,具备了创作的自主性。
“创造力三脚架(The Creative Tripod)”:技能、鉴赏力和想象力
DARCI系统的开发者们试图向人们表明,意向性和自主性是一个具有创造力的创作过程所必不可少的,并进一步通过DARCI系统展示了,意向性和自主性不仅仅能够在以人类为主体的创作过程中体现,也能够在算法化的创作过程中体现。而人工智能学者Colton在2008年的论文《计算系统中的创造力和对创造力的感知(Creativity Versus the Perception of Creativity in Computational Systems)》[1] 中,对于“什么样的创作过程是具有创造性的”这个问题,给出了一个更加系统性的回答——“创造力三脚架(The Creative Tripod)”。
“创造力三脚架(The Creative Tripod)”指的是Colton所提出的构成创造力行为的三大必备要素——技能(Skill),鉴赏力(Appreciation)和想象力(Imagination)。
在Colton看来,一个系统要被称作是具有创造力的,它的行为必须表现出这三大要素。如果一个系统不具有它所在创作领域技能, 那么它就无法产生出这个领域的像样的作品;如果这个系统不具有鉴赏力,那么它就无法产生有价值的作品;如果这个系统不具有想象力,那么它就无法产生具有独创性的作品(最多只能模仿现有的作品)。
因此,当我们面对一个具体的系统时,就可以通过评估这个系统在技能、鉴赏力和想象力上的表现来评估这个系统的创造力表现。
(下面我们要以第三章中介绍的三个人工创造力系统为例示范如何应用创造力三脚架理论进行创造力评估。推荐读者首先阅读第三章:))
比如,我们在第三章中介绍过的概念整合系统DIVAGO——它接收两个知识领域的编码,能够自动生成融合这两个知识领域的新概念,比如输入分别关于鸟和马的概念网络而生成类似“飞马”这样的新概念。
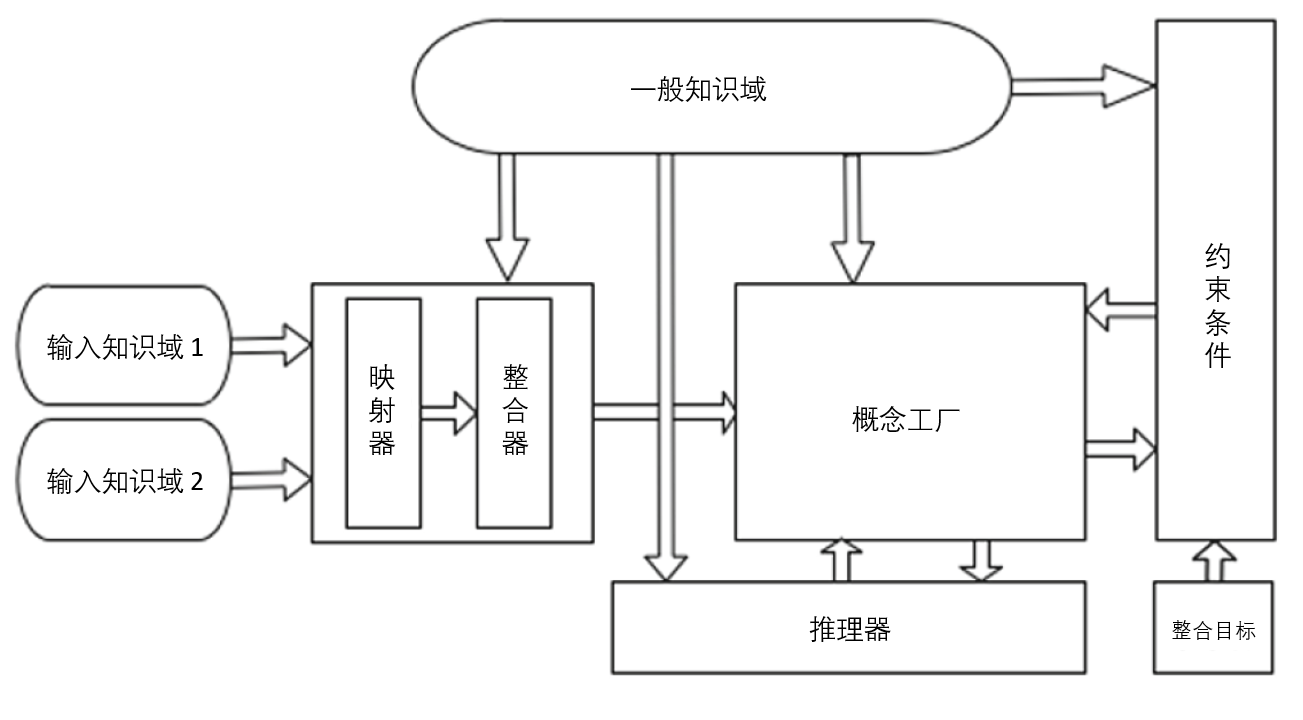
- DIVAGO有一套机制能够保证生成的概念至少都是在逻辑上站得住脚的,不会自相矛盾——这可以看作它在技能上的表现
- DIVAGO编码了Fauconnier和Turner的概念整合“最优原则(Optimality Principle)”,在最后输出概念时会倾向于选择那些在最优原则上得分高的——这可以看作它在鉴赏力上的表现。
- 最后,给定两个输入概念网络,DIVAGO要探索将这两个网络上的节点进行相互映射的所有可能的方式得到的整合概念网络,这是一个相当庞大的搜索空间(分别含有5个和7个概念节点的两个输入概念网络,已经足以产生67108864个整合概念网络的可能性),足以给最后的输出带来极其丰富的可能性——这可以看作是DIVAGO在想象力上的表现。
而如果我们考察另一个概念整合系统Metaphor Eyes,结果就很不一样。Metaphor Eyes能够通过利用谷歌搜索引擎的关键字补全功能自动从互联网上获取概念整合所需要的知识库,用户在Metaphor Eyes网页的文本框中输入关联两个名词的一个简单隐喻句子(比如“Google is a cult(谷歌是邪教)”),Metaphor Eyes就会返回一系列两个名词的共同特征,作为对用户输入的隐喻成立的支持(比如“Google worships celebrities like cult(谷歌就像邪教那样搞个人崇拜)”)。

- 给定两个输入概念,Metaphor Eyes不对这两个概念进行任何语义上的处理,以至于最后整合出的新概念很可能是完全意味不明的——这个角度来说可以认为它缺乏创作领域内的技能。
- 虽然不考虑含义,但Metaphor Eyes还是会倾向于选择输入概念各自在搜索引擎上出现频率高的特征来进行整合——这意味着它具有一定的鉴赏力,但它的鉴赏力就跟那些没有自己的时尚品味只知道跟风穿搭的人们一样有限。
- Metaphor Eyes没有任何语义空间的概念,其搜索空间仅仅是两个输入概念在搜索引擎上出现的特征的总和,相比DIVAGO来说相当有限——如果用人格化的方式来描述,Metaphor Eyes是相当缺乏想象力的。
最后我们再来看Deep Dream和Deep Style Transfer,两者都是基于深度神经网络的图像生成系统。Deep Dream的原理是自动化地修改输出图片上各个像素的RGB数值,来使得神经网络读取这个图片之后的输出逼近给定的结果。Neural Style Transfer的原理则是修改输出图片上各个像素的RGB值,来使得输出图片在内容上与用户输入的第一张图片尽可能相似,在风格上与用户输入的第二张图片尽可能相似。

- Deep Dream和Deep Style Transfer中的基础神经网络都是在数量庞大的图片数据集上训练得到,神经网络的参数以统计的方式“估计”了一张“像样”的图片应该是什么样子的——因此可以认为它在一般图像所覆盖的范围内是具有一定技能的。
- Deep Dream和Deep Style Transfer的原理都是调整输出图片上的像素点,使得输出图片的某些宏观统计特征尽可能接近给定的输入——这意味着它只是在模仿输入,而很难说它具有自己的鉴赏力。
- Deep Dream和Deep Style Transfer的搜索空间是训练过程中算法自发产生的图像特征表示组成的向量空间,因此只要训练数据足够庞大、神经网络的参数足够多,这个搜索空间就能具有可观的规模——因此Deep Dream和Deep Style Transfer的想象力,在数据集足够庞大的前提下,也是可以得到认可的。
最后结论:DIVAGO比起Metaphor Eyes来,在技能、鉴赏能力和想象力上全部胜出,因此毫无疑问是比Metaphor Eyes更加具有创造力的系统。Deep Dream和Deep Style Transfer在技能和想象力都有不错的表现,但缺乏鉴赏力,在这个意义上它的创造力是有争议的。
当然,在算法的语境下,分别什么是技能、鉴赏力和想象力,仍然是非常有争议的问题。上面的分析只是基于对这三个问题的一种理解,在不同的理解下当然可能得到不同的结论。创造力三脚架的理论最核心的贡献是在于,将“如何可计算地实现创造力”的问题,转变为了“如何可计算地实现技能”、“如何可计算地实现鉴赏力”、”如何可计算地实现想象力“这三个稍微容易一些的子问题。
创造力三脚架理论中所说的鉴赏力,由于要求算法或者系统自身对作品有一定的评判标准、以这个评判标准去筛选和打磨作品并决定最后输出的作品,可以认为对应于DARCI系统部分所提到的意向性的概念。而创造力三脚架理论中所说的想象力,本质上是要求算法或系统自身所产生的输出具有足够丰富的可能性——丰富到用户无法根据自己的输入就能够预测输出,从而允许各种各样的涌现式(Emergent)结果的出现——因此可以认为对应于DARCI系统部分所提到的自主性的概念。
从另一个角度对创造力三脚架理论进行解读,如果使用我们在第一章中介绍过的概念空间(Conceptual Space)探索这套框架下的语言,那么一个创作算法可以被看作是概念空间中的搜索算法。技能的概念就对应于这个搜索算法在有效范围内搜索,不跑出概念空间的能力;鉴赏力的概念对应于这个搜索算法所使用的价值函数与这个领域的人类观众脑中对作品好坏的评判的相关程度;想象力的概念则对应于这个搜索算法能够覆盖到的概念空间范围有多庞大。
总结
这一章,我们讨论了创造力对创作过程的要求。首先介绍了一个已经实现的图像生成系统DARCI,讨论它的创作机理对于“算法本身如何表现出创造力”这个问题的启示,接着介绍了Colton的创造力三脚架理论(Creative Tripod),将创造力对创造过程的要求总结为技能、鉴赏力和想象力三个要素;在对第三章介绍过的三个创造力系统的分析中,简单地考察了这三个要素在算法的语境下能够有些什么样的表现形式。
对算法过程进行评估的需要也是人工创造力与一般意义上的人工智能的一大重要区别。我们现今看到的大多数(尤其是基于深度学习)的人工智能系统,其评估更多的是集中在系统输出上的(统计性)评估。而过程层面的评估要求算法不仅仅在统计意义上要更倾向于产生有效的输出,也要求系统具有一定的透明性(Transparency)和可解释性(Explanability)。
Colton在他的关于创造力三脚架的论文中,提到一个有意思的现象:当人们看到一件有创意的优秀作品,如果它的作者是人类,人们很容易接受将这个人类作者称为“有创造力”的;而如果这件作品是来源于一个算法,人们更倾向于将创造力归功于这个算法的开发者。
Colton认为这是一种偏见,或者说双重标准(Double Standard)。事实上这件作品的人类作者可能只是一个死板地去实现老师的创新观点的学生;而在这件作品是由算法产生的情况下,算法的开发者本人也可能在看到这件作品后感到惊喜并受到启发。
而如果运用创造力三脚架的理论去分析每种情况,就能得到更加客观的结论。如果作品的作者只是一个死板地去实现老师的创新观点的学生,那么学生本人可能只贡献了创造力三要素中的技能部分,鉴赏力和想象力的来源则是老师——这个时候,说这个学生具有创造力就是不恰当的,而应该说是这个学生和老师共同组成的系统是具有创造力的。这种多人共同形成一个创造力主体的情形,其实在现在这个艺术创作工业化的时代非常多见。
而如果作品是由一个算法产生的,就可能存在更多不同的情况。如果算法仅仅只是大规模实现某个开发者自己想到的创作套路(比如作曲中将某几个音组成的音阶在一定节奏下排列组合),这时候算法更多只是对现有风格的摹仿(Pastiche),技能和鉴赏力都是来自于发现了这种套路的有效性的开发者,而算法只是通过在一定空间内的排列组合帮助开发者想象这个套路在不同情况下的表现。而另一种极端情况,开发者本人可能对这个创作领域毫无专业知识,使用类似遗传算法这样的极其具有一般性的搜索算法来产生作品,他可能就只贡献了鉴赏力(甚至有些情况下连鉴赏力都没有贡献),而算法贡献了剩下的要素。

在这个例子中我们看到,创造力三脚架中的三个要素,不一定是要由同一个主体来提供的。如果我们能够接受多个人类组成的系统是创造力的主体,我们是不是也能够接受,人类和算法组成的系统是创造力的主体呢?
而这正是共同创造力(Co-creativity)的概念,我们下一章就来讨论它。
参考文献
[1] Colton, Simon. "Creativity Versus the Perception of Creativity in Computational Systems." AAAI spring symposium: creative intelligent systems. Vol. 8. 2008.
[2] Ventura D. (2019) Autonomous Intentionality in Computationally Creative Systems. In: Veale T., Cardoso F. (eds) Computational Creativity. Computational Synthesis and Creative Systems. Springer, Cham. https://doi.org/10.1007/978-3-319-43610-4_3
[3] Heath, D., Norton, D., & Ventura, D. (2013). Autonomously communicating conceptual knowledge through visual art. In Proceedings of the 4th International
Conference on Computational Creativity (pp. 97–104).
[4] Heath, D., Norton, D., & Ventura, D. (2014). Conveying semantics through visual metaphor. ACM Transactions on Intelligent Systems and Technology, 5(2),
article 31.
[5] Heath, D., & Ventura, D. (2016). Creating images by learning image semantics using vector space models. In Proceedings of the Association for the Advancement
of Artificial Intelligence (pp. 1202–1208).
[6] Norton, David & Heath, Derral & Ventura, Dan. (2012). Establishing Appreciation in a Creative System.